Hadoop & Spark
文章目录
主要介绍 Hadoop 和 Spark 的关系和联系。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。所以使用Hadoop则可以抛开spark,而直接使用Hadoop自身的mapreduce完成数据的处理。Spark是不提供文件管理系统的,但也不是只能依附在Hadoop上,它同样可以选择其他的基于云的数据系统平台,但spark默认的一般选择的还是hadoop。
HDFS是一个采用Master/Slave模式的高度容错的分布式文件系统,DataNode节点用于存储数据,NameNode节点维护集群内的元数据,Map负责对数据进行打散,Reduce负责对数据进行聚合,核心步骤为:首先将计算机任务拆分成若干个Map任务,然后分配到不同的节点上执行,每一个Map任务处理数据中的一部分,完成后生产的的中间结果,保存在磁盘中,Reduce将前面的若干个Map的输出汇总到一起输出。
Hadoop集群由一个Master主节点和若干个Slave节点组成。其中,Master节点上运行NameNode和JobTracker守护进程;Slave节点上运行DataNode和TaskTracker守护进程。
- Namenode 是整个文件系统的管理节点。它维护着1.整个文件系统的文件目录树,2.文件/目录的元信息和每个文件对应的数据块列表。3.接收用户的操作请求。
- dataNode提供真实文件数据的存储服务。
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。
- HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block. 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。 (这样设置可以减轻namenode压力,因为namonode维护者文件与数据块列表的对应大小)
- Replication。多复本。默认是三个。(hdfs-site.xml的dfs.replication属性)
首先了解一下Mapreduce,它最本质的两个过程就是Map和Reduce,Map的应用在于我们需要数据一对一的元素的映射转换,比如说进行截取,进行过滤,或者任何的转换操作,这些一对一的元素转换就称作是Map;Reduce主要就是元素的聚合,就是多个元素对一个元素的聚合,比如求Sum等,这就是Reduce。
spark 的优势
- 每一个作业独立调度,可以把所有的作业做一个图进行调度,各个作业之间相互依赖,在调度过程中一起调度,速度快。(形成了一个有向无环图)
- 所有过程都基于内存,所以通常也将Spark称作是基于内存的迭代式运算框架。
- spark提供了更丰富的算子,让操作更方便。
- 更容易的API:支持Python,Scala和Java
其实spark里面也可以实现Mapreduce,但是这里它并不是算法,只是提供了map阶段和reduce阶段,但是在两个阶段提供了很多算法。如Map阶段的map, flatMap, filter, keyBy,Reduce阶段的reduceByKey, sortByKey, mean, gourpBy, sort等。
Spark 算子大致可以分为以下两类: 1.Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。 2.Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。 怎么区分transformation算子和action算子呢? transformation算子一定会返回一个rdd,action大多没有返回值,也可能有返回值,但是一定不是rdd.
Spark 中的RDD就是为了解决这种问题而开发出来的,Spark使用了一种特殊设计的数据结构,称为RDD。RDD的一个重要特征是,分布式数据集可以在不同的并行环境当中被重复使用,这个特性将Spark和其他并行数据流模型框架(如MapReduce)区别开。
RDD 的算子主要分成2类,action 和 transformation。这里的算子概念,可以理解成就是对数据集的变换。action 会触发真正的作业提交,而 transformation 算子是不会立即触发作业提交的。每一个 transformation 方法返回一个新的 RDD。只是某些 transformation 比较复杂,会包含多个子 transformation,因而会生成多个 RDD。这就是实际 RDD 个数比我们想象的多一些 的原因。通常是,当遇到 action 算子时会触发一个job的提交,然后反推回去看前面的 transformation 算子,进而形成一张有向无环图。
列举一些 Transformation 和 Action Transformantion: Map, Filter, FlatMap, Sample, GroupByKey, ReduceByKey, Union, Join, Cogroup, MapValues, Sort, PartionBy
Action: Collect, Reduce, Lookup, Save
RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ,而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。
RDD 中所有的 Transformation 都是惰性的,也就是说,它们并不会直接计算结果。相反的它们只是记住了这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给 Driver 的 Action 时,这些 Transformation 才会真正运行。
这个设计让 Spark 更加有效的运行。
区别
-
数据处理速度
-
spark 是支持许多机器学习的模型(分类、聚类、回归、协同过滤),而 hadoop 中的MapReduce 是不支持的.
-
数据安全恢复:Hadoop每次处理的后的数据是写入到磁盘上,所以其天生就能很有弹性的对系统错误进行处理;spark的数据对象存储在分布于数据集群中的叫做弹性分布式数据集中,这些数据对象既可以放在内存,也可以放在磁盘,所以spark同样可以完成数据的安全恢复。
基于内存的Spark和基于磁盘的Hadoop也是一个区别。
Spark的核心在于RDD,可以理解为包含许多操作接口的数据集合,主要有Transformation(lazy)和action两类算子。spark根据RDD之间的依赖关系切分成不同的阶段stage,RDD之间的转换的思想是 lazy的,也就是说不是实际发生的,而是以有向无环图的方式记录,通过一个Action算子,将积累的所有算子一次性执行。
spark 和mapreduce 的区别:
- 性能
Spark在内存中处理数据,而MapReduce是通过map和reduce操作在磁盘中处理数据。所以从这方面讲Spark的性能是超过MapReduce的。但是当数据量比较大,无法全部读入内存时,MapReduce就比较有优势。当涉及需要重复读取同样的数据进行迭代式计算的时候,Spark比较有优势;但是当涉及到单次读取,类似ETL操作任务时,适合用MapReduce进行处理。
- 容错
当执行中途失败时,MapReduce会从失败处继续执行,因为它是依赖于硬盘驱动器的。但是Spark就必须从头开始执行,这样MapReduce相对节省了时间。
- 应用场景
MapReduce主要是进行离线计算处理,计算一些已存在的数据,比如对已存在的订单或者日志进行分析。而Spark可以应用在一些实时查询和迭代分析的场景,比如像推荐系统。
spark的有几种部署模式,每种模式特点?
- 本地模式
Spark不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。方便调试,本地模式分三类 local:只启动一个executor local[k]: 启动k个executor local[*]:启动跟cpu数目相同的 executor
- standalone模式
分布式部署集群,自带完整的服务,资源管理和任务监控是Spark自己监控,这个模式也是其他模式的基础
- Spark on yarn模式
分布式部署集群,资源和任务监控交给yarn管理 粗粒度资源分配方式,包含cluster和client运行模式 cluster 适合生产,driver运行在集群子节点,具有容错功能 client 适合调试,dirver运行在客户端
spark on yarn 的支持两种模式 1)yarn-cluster:适用于生产环境; 2)yarn-client:适用于交互、调试,希望立即看到app的输出
Spark核心技术原理透视二(Spark运行模式 谈谈Spark运行模式
- Spark On Mesos模式
spark有哪些组件?
master:管理集群和节点,不参与计算。 worker:计算节点,进程本身不参与计算,和master汇报。 Driver:运行程序的main方法,创建spark context对象。 spark context:控制整个application的生命周期,包括dagsheduler和task scheduler等组件。 client:用户提交程序的入口。
spark架构与生态
- Spark Core
- Spark SQL
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX
hadoop分为 MapReduce 与 分布式文件系统(HDFS)
- MapReduce:
仅支持Map和Reduce两种操作 Map中间结果需要写磁盘 任务调度和启动开销大 无法充分利用内存 Map和Reduce都需要排序 不适合迭代计算
- Spark:
丰富的API(Java、Scala、Python、R四种语言,sort、join等高效算子) DAG执行引擎,中间结果不落盘 线程池模型减少task启动开销 充分利用内存,减少磁盘IO 避免不必要的排序操作 适合迭代计算,比如机器学习算法
- RDD
spark 涉及的核心概念就是resilient distributed dataset (RDD),rdd是具有容错性的数据集合,并可以并行数据计算。有两种方法可以创建rdd,第一种就是parallelizing 方法:序列化存在driver program 中的集合,见下方代码
|
|
并parallelize 方法中可以指定数据分区参数,并每个分区对应一个task 如下面代码
|
|
{kind=link}
窄依赖是指每个父RDD的Partition最多被子RDD的一个Partition所使用,例如map、filter,见上左图 宽依赖是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey等
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、元素可并行计算的集合。
RDD的弹性表现: 1、弹性之一:自动的进行内存和磁盘数据存储的切换; 2、弹性之二:基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错); 3、弹性之三:Task如果失败会自动进行特定次数的重试(默认4次); 4、弹性之四:Stage如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段);只计算失败的数据分片;
RDD的持久化是spark的一个重要的特性,当你把RDD持久化,每个Node会存储RDD的分区在内存,在其他action中用到此rdd的时候,就不用从头转化,而是直接使用。你可以用persist或者cache方法持久化rdd,Spark的 缓 存是一个容 错 的技 术 -如果RDD的任何一个分区 丢 失,它 可以通 过 原有的 转换 ( transformations )操作自 动 的重复 计 算并且 创 建出 这 个分区。另外,每一个RDD可以选择不同的持久化级别.
RDD 的创建方式主要有2种:
- 并行化(Parallelizing)一个已经存在与驱动程序(Driver Program)中的集合如set、list;
- 读取外部存储系统上的一个数据集,比如HDFS、Hive、HBase,或者任何提供了Hadoop InputFormat的数据源.也可以从本地读取 txt、csv 等数据集
RDD 的操作函数(operation)主要分为2种类型 Transformation 和 Action
| 类别 | 函数 | 区别 |
|---|---|---|
| Transformation | Map,filter,groupBy,join, union,reduce,sort,partitionBy | 返回值还是 RDD,不会马上 提交 Spark 集群运行 |
| Action | count,collect,take,save, show | 返回值不是 RDD,会形成 DAG 图,提交 Spark 集群运行 并立即返回结果 |
Spark运行模式?
(这四种运行模式是需要好好看看的) Spark On Local Spark On Local Cluster(Spark Standalone) Spark On Yarn Spark Cluster模式
常见的Spark的性能瓶颈有哪些?
影响性能的主要因素是Shuffle,可以优化代码减少不必要的Stage数量及Shuffle数据量以改进Shuffle性能。由于Shuffle的中间结果数据都是要落磁盘的,所以可以考虑给服务器加SSD(一般100G左右就够了),将Spark的tmp目录设置为SSD目录,性能提升20%左右。
其次是IO,网络IO建议上万兆网络(这也是影响Shuffle性能的一个因素),对于磁盘IO,一般是给服务器设置多块单盘,不要做RAID!挂载磁盘时设置noatime,提高磁盘IO性能。
最后是CPU,Spark做计算如果数据已经加载到内存了,CPU就比较容易成为计算瓶颈,代码方面主要是优化计算,减少计算量,同时也要关注计算任务是否有数据倾斜的现象;硬件方面只能换性能更强劲的CPU了。
|
|

大部分数据倾斜的原理就类似于下图,很明了,因为数据分布不均匀,导致大量的数据分配到了一个节点。
如何解决这种问题 1.业务逻辑,我们从业务逻辑的层面上来优化数据倾斜,比如上面的例子,我们单独对这两个城市来做count,最后和其它城市做整合。 2.程序层面,比如说在Hive中,经常遇到count(distinct)操作,这样会导致最终只有一个reduce,我们可以先group 再在外面包一层count,就可以了。 3.调参方面,Hadoop和Spark都自带了很多的参数和机制来调节数据倾斜,合理利用它们就能解决大部分问题。
硬盘有机械硬盘(HDD)和固态硬盘(SSD)
针对不同的作业类型,在对集群进行良好配置的提前下,spark作业最耗时的部分往往是因为集群资源的限制,主要体现在三个方面:CPU、DISK IO、NETWORK IO。spark将作业拆分成的单元是stage,不同的stage内部执行不同的逻辑。stage内部既有io操作,也有cpu计算操作,还会有network(主要是shuffle引起的),当这三个部分其中某一部分所占的比例较大时,在资源占用上就会体现出这一部分的bottleneck。例如,
这样一个stage,就是简单的从hdfs中读取文本数据计算有多少行。几乎没有cpu操作,shuffle的量也很小,主要的操作在DISK IO上,因此,这个stage耗时最长的部分就是在磁盘读写上。因此,判断一个作业最耗时的部分,需要实际的去分析stage的执行逻辑,结合实际的资源占用情况,这样才能的到准确完整的答案
对于不同的计算场景,io,shuffle,cpu都有可能成为计算瓶颈。 一般来说,做统计的时候io是最大的瓶颈,做数据挖掘的时候比较慢的是shuffle和cpu。
Shuffle的作用是什么?
Shuffle的中文解释为“洗牌操作”,可以理解成将集群中所有节点上的数据进行重新整合分类的过程。其思想来源于hadoop的mapReduce,Shuffle是连接map阶段和reduce阶段的桥梁。由于分布式计算中,每个阶段的各个计算节点只处理任务的一部分数据,若下一个阶段需要依赖前面阶段的所有计算结果时,则需要对前面阶段的所有计算结果进行重新整合和分类,这就需要经历shuffle过程。 在spark中,RDD之间的关系包含窄依赖和宽依赖,其中宽依赖涉及shuffle操
filter map flatMap等操作属于transform,rdd经过若干的transform,直到action(如take count isEmpty foreach foreachPartition)才会真正执行。
spark 中常见的action 算子 Action类算子也是一类算子(函数)叫做行动算子,如foreach,collect,count等。Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序(就是我们编写的一个应用程序)中有几个Action类算子执行,就有几个job运行。
reduce
通过函数func聚集数据集中的所有元素,这个函数必须是关联性的,确保可以被正确的并发执行
collect 在driver的程序中,以数组的形式,返回数据集的所有元素,这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用
count 返回数据集的元素个数
first 返回数据集的第一个元素(类似于take(1))
take 返回一个数组,由数据集的前n个元素组成。
takeSample(withReplacement,num,seed)
withReplacement:结果中是否可重复 num:取多少个 seed:随机种子
返回一个数组,在数据集中随机采样num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定的随机数生成器种子
saveAsTextFile
saveAsTextFile用于将RDD以文本文件的格式存储到文件系统中
hadoop: java hive: jave storm: clojure, jstorm java kafka: scala spark: scala flink: scala
Spark is a fast and general engine for large-scale data processing.
- speed, run programs up to 100x faster than hadoop mapreduce in memory, or 10x faster on disk.
- ease of use, Java, Scala, Python, R
- combine SQL(离线任务), streaming(实时任务), and complex analytics.
- run everywhere, Spark runs on Hadoop, Mesos, standalone(这个是spark 自己的), or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.
有三种下载方式
- spark 官网
- github 托管
- arkive.apache.cn
collect是收集起来,然后展示。 spark 中的方法通常是被称为算子
什么是 RDD?
RDD( Resilient distributed dataset) 叫做分布式数据集,是Spark 中最基本的数据抽象,它代表一个不可变,可分区,里面的位置可并行计算的集合。RDD 具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性,RDD 允许用户执行多个查询时显式将工作集缓存在内存中,后序的查询能够重用工作集,极大的提供了查询的速度。
RDD 的属性?(多看)
生成RDD的两种方式
一种是使用textFile() 一种使用parallelize()
两种类型的算法 主要是从运行效率角度考虑
transformation(转换类型),仅仅记录一个运算过程,只有当 action类型的动作产生,那么才会运行。 action(动作类型),生成一个任务就提交了集群上进行计算,所以一定要记住 action 类型的算子,基于优化的角度,慎用。
查找官方 spark programming guide, 官网中的 transformation 是常用的类型,不是全部的转换类型。
存储mysql 数据库,使用 mappartitions 而不是 map进行操作,减少调用的次数。
常见的transformation 类型
- map (func) 每一个元素 一个个根据 func 进行处理
- filter 需要给定一个filter 的逻辑
- flatmap 先是压平,然后处理
- mappartitions 取出数据的分区进行遍历,一个个分区进行处理
- sample 抽样
- union
- intersection
- distinct 去重
- groupbykey 使用key 进行分组,相同key 就分到一块
- reducebykey 使用key 来做聚合
- aggregatebykey
- sortbykey 使用key 来做排序
- join 左连接 和右连接
- repartition 重新分区
** 常见的action **
- reduce 聚合
- collect
- count
- first 拿到第一个元素
- take (n) 拿到前 n 个元素
- take Sample 抽样
- takeOrdered 排序之后再去取元素
- saveAsTextFile(path) 存储
- foreach 没有返回值(和map 不一样,map 处理之后是有返回值的), 比如说拿到数据并且存储到数据库
MapReduce 6个过程

如何去优化 shuffle 过程? 这个博客讲解的很好hadoop 中的shuffle
集中式和分布式的讲解
集中式开发:是将项目集中存放在中央服务器中,在工作的时候,大家只在自己电脑上操作,从同一个地方下载最新版本,然后开始工作,做完的工作再提交给中央服务器保存。使用一句话概括:一个主机有多个终端,终端没有数据处理能力,仅仅负责数据的录入和输出。
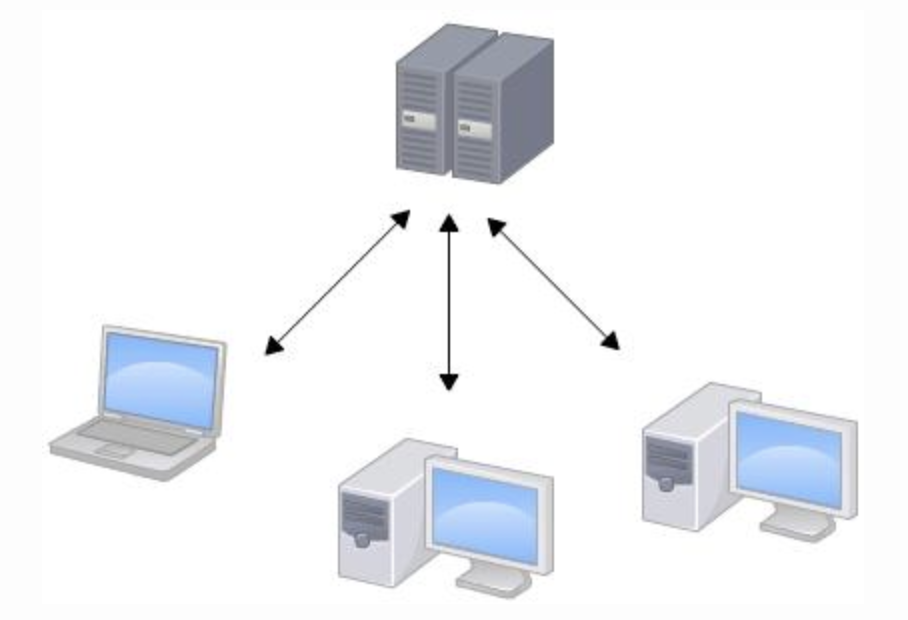
优点:
集中式架构的优势在于可靠性、一致性和稳定性
部署简单
缺点:
需要联网才能工作,如果在局域网,需要带宽够大;
缺点在于不适用于非结构化数据,特别是在支撑力有限的前提下,但对顶层设计的要求偏高
应用场景:
然而由于历史上的种种原因,集中式架构多用于传统的银行、电信、交通、医疗等行业,操作系统、中间件、数据库等“基础软件”多为闭源商用系统,“稳定、安全”几乎是集中式架构的代名词。
分布式开发:只要提供一台电脑作为版本集中存的服务器放就够了,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它也一样干活,只是交换修改不方便而已。
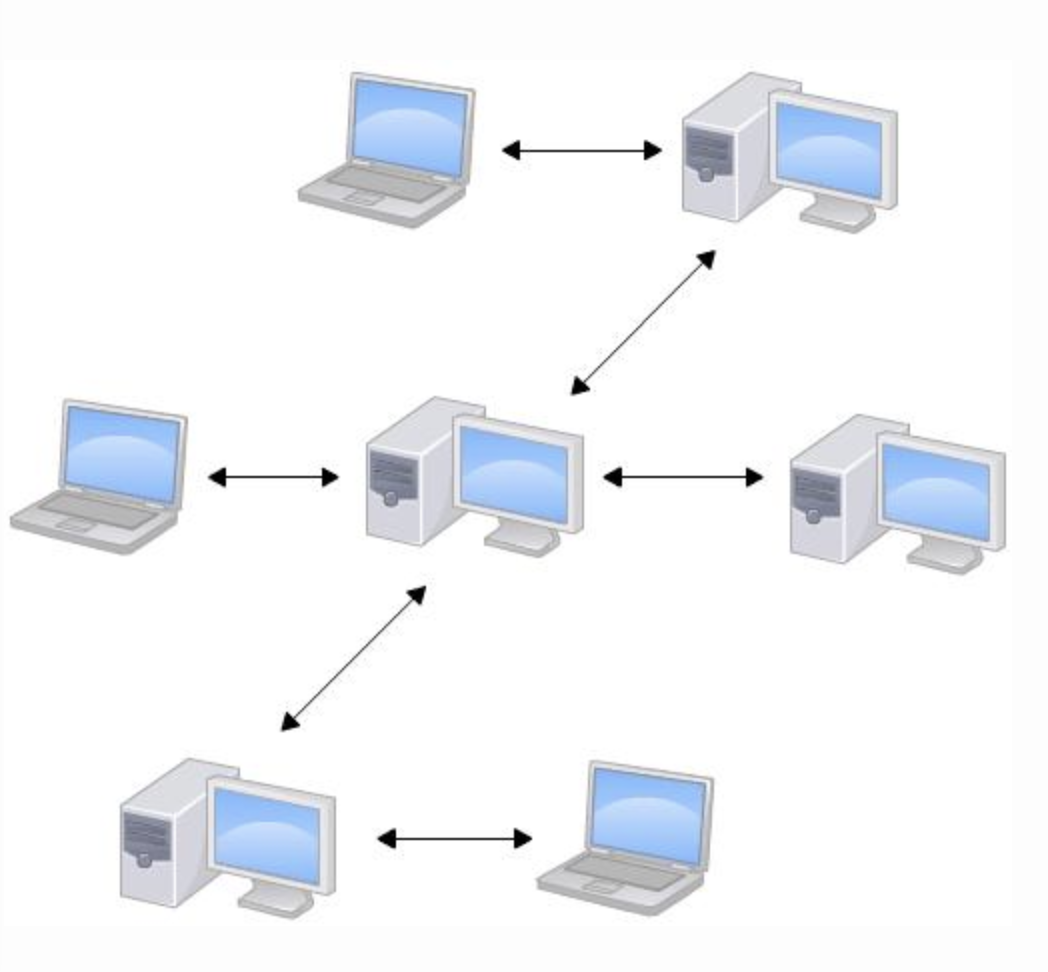
优点
安全性高:某一个节点坏了,也是没有关系,随便从另一节点上拷贝进行了。
性价比更高,处理能力强,可扩展性高。
缺点
应用场景 :
互联网公司
文章作者 jijeng
上次更新 2019-04-15