记录图像分类过程中常见的优化点(工程角度)。
数据相关
- data augmentation
resize, crop, rotation, flip,
shearing (这个操作是不是没有实验过)
这里有一个技巧 resize(256, 256) 然后random crop(224, 224) 这个样子
使用 ColorJitter:改变图像的亮度、对比度和饱和度
必备的常规操作: totensor(), normalize()
-
查看data augmentation之后数据的 viewer
-
分成train val 和test 三部分的data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
data_dir = os.path.join(ROOT, 'CUB_200_2011')
images_dir = os.path.join(data_dir, 'images')
train_dir = os.path.join(data_dir, 'train')
test_dir = os.path.join(data_dir, 'test')
# 对于外层文件夹这样写,对于内层文件夹就可以 os.makedirs() 操作了
if os.path.exists(train_dir):
shutil.rmtree(train_dir)
if os.path.exists(test_dir):
shutil.rmtree(test_dir)
os.makedirs(train_dir)
os.makedirs(test_dir)
classes = os.listdir(images_dir)
for c in classes:
class_dir = os.path.join(images_dir, c)
images = os.listdir(class_dir)
n_train = int(len(images) * TRAIN_RATIO)
train_images = images[:n_train]
test_images = images[n_train:]
os.makedirs(os.path.join(train_dir, c), exist_ok = True)
os.makedirs(os.path.join(test_dir, c), exist_ok = True)
# 这种代码的书写也是非常有条理的
for image in train_images:
image_src = os.path.join(class_dir, image)
image_dst = os.path.join(train_dir, c, image)
shutil.copyfile(image_src, image_dst)
for image in test_images:
image_src = os.path.join(class_dir, image)
image_dst = os.path.join(test_dir, c, image)
shutil.copyfile(image_src, image_dst)
|
类似这种code 结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
# Image transformations
image_transforms = {
# Train uses data augmentation
'train':
transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224), # Image net standards
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # Imagenet standards
]),
# Validation does not use augmentation
'valid':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
]),
# Test does not use augmentation
'test':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
]),
}
# Datasets from folders
traindir = "data/train"
validdir = "data/val"
testdir = "data/test"
data = {
'train':
datasets.ImageFolder(root=traindir, transform=image_transforms['train']),
'valid':
datasets.ImageFolder(root=validdir, transform=image_transforms['valid']),
'test':
datasets.ImageFolder(root=testdir, transform=image_transforms['test'])
}
# Dataloader iterators, make sure to shuffle
dataloaders = {
'train': DataLoader(data['train'], batch_size=batch_size, shuffle=True,num_workers=10),
'val': DataLoader(data['valid'], batch_size=batch_size, shuffle=True,num_workers=10),
'test': DataLoader(data['test'], batch_size=batch_size, shuffle=True,num_workers=10)
}
|
Boats_Model.ipynb中有一整套的code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# Image transformations
image_transforms = {
# Train uses data augmentation
'train':
transforms.Compose([
transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224), # Image net standards
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225]) # Imagenet standards
]),
# Validation does not use augmentation
'valid':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
# Test does not use augmentation
'test':
transforms.Compose([
transforms.Resize(size=256),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
|
这个code是用来查看 data augmentation 之后的效果的
1
2
3
4
5
6
7
8
9
10
|
ex_img = Image.open('/home/rahul/projects/compvisblog/data/train/cruise ship/cruise-ship-oasis-of-the-seas-boat-water-482183.jpg')
t = image_transforms['train']
plt.figure(figsize=(24, 24))
for i in range(16):
ax = plt.subplot(4, 4, i + 1)
_ = imshow_tensor(t(ex_img), ax=ax)
plt.tight_layout()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# Datasets from folders
data = {
'train':
datasets.ImageFolder(root=traindir, transform=image_transforms['train']),
'valid':
datasets.ImageFolder(root=validdir, transform=image_transforms['valid']),
'test':
datasets.ImageFolder(root=testdir, transform=image_transforms['test'])
}
# Dataloader iterators, make sure to shuffle
dataloaders = {
'train': DataLoader(data['train'], batch_size=batch_size, shuffle=True,num_workers=10),
'val': DataLoader(data['valid'], batch_size=batch_size, shuffle=True,num_workers=10),
'test': DataLoader(data['test'], batch_size=batch_size, shuffle=True,num_workers=10)
}
|
Iterable 遍历
1
2
3
4
5
6
7
8
9
10
11
12
|
# Iterate through the dataloader once
trainiter = iter(dataloaders['train'])
features, labels = next(trainiter)
features.shape, labels.shape
categories = []
for d in os.listdir(traindir):
categories.append(d)
n_classes = len(categories)
print(f'There are {n_classes} different classes.')
|
还有一个版本的data split 方式:来源https://heartbeat.fritz.ai/transfer-learning-with-pytorch-cfcb69016c72
定义三个transforme
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
train_transforms = transforms.Compose([transforms.RandomResizedCrop(size=256, scale=(0.8, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.ColorJitter(),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224), # Image net standards
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
test_transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
validation_transforms = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
|
接着上一条,按照一定的比例将 data 分成 train_data, val_data 和 test_data
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
#Loading in the dataset
train_data = datasets.ImageFolder(img_dir,transform=train_transforms)
# number of subprocesses to use for data loading
num_workers = 0
# percentage of training set to use as validation
valid_size = 0.2
test_size = 0.1
# obtain training indices that will be used for validation
num_train = len(train_data)
indices = list(range(num_train))
np.random.shuffle(indices)
valid_split = int(np.floor((valid_size) * num_train))
test_split = int(np.floor((valid_size+test_size) * num_train))
valid_idx, test_idx, train_idx = indices[:valid_split], indices[valid_split:test_split], indices[test_split:]
print(len(valid_idx), len(test_idx), len(train_idx))
# define samplers for obtaining training and validation batches
train_sampler = SubsetRandomSampler(train_idx)
valid_sampler = SubsetRandomSampler(valid_idx)
test_sampler = SubsetRandomSampler(test_idx)
# prepare data loaders (combine dataset and sampler)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=32,
sampler=train_sampler, num_workers=num_workers)
valid_loader = torch.utils.data.DataLoader(train_data, batch_size=32,
sampler=valid_sampler, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(train_data, batch_size=32,
sampler=test_sampler, num_workers=num_workers)
|
思路很清晰:设置了param 是否可以train
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
for param in model.parameters():
param.require_grad = False
fc = nn.Sequential(
nn.Linear(1024, 460),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(460,2),
nn.LogSoftmax(dim=1)
)
model.classifier = fc
criterion = nn.NLLLoss()
#Over here we want to only update the parameters of the classifier so
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=0.003)
model.to(device)
|
这样得到 train val test dataset。
至少从命名规范上讲,这个是非常规范的。
1
2
3
4
5
|
# Split into train+val and test
X_trainval, X_test, y_trainval, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=69)
# Split train into train-val
X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, test_size=0.1, stratify=y_trainval, random_state=21)
|
-
num worker
大多数的瓶颈在于CPU和GPU两个处理的速度不匹配,CPU的投喂不能满足GPU的需求。
1
2
3
4
5
6
7
8
9
10
|
import multiprocessing
NUM_WORKERS = multiprocessing.cpu_count()
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=4, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=4, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE,
shuffle=False, num_workers=NUM_WORKERS)
|
构建数据集的class(如果想要得到batch 的数据,那么是可以写class,得到item或者batch的数据)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class ImageDataset(torch.utils.data.Dataset):
def __init__(self, df, image_dir, mode="train"):
self.df = df
self.mode = mode
self.image_dir = image_dir
transform_list = [
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]
self.transforms = transforms.Compose(transform_list)
def __getitem__(self, index):
id_ = self.df["id"].iloc[index]
filepath = "{}/{}/{}/{}/{}/{}.jpg".format(image_dir, self.mode, id_[0], id_[1], id_[2], id_)
img = Image.open(filepath)
img = self.transforms(img)
if self.mode == "train":
return {"image": img, "target": self.df["landmark_id"].iloc[index]}
elif self.mode == "test":
return {"image": img}
def __len__(self):
return self.df.shape[0]
|
模型相关
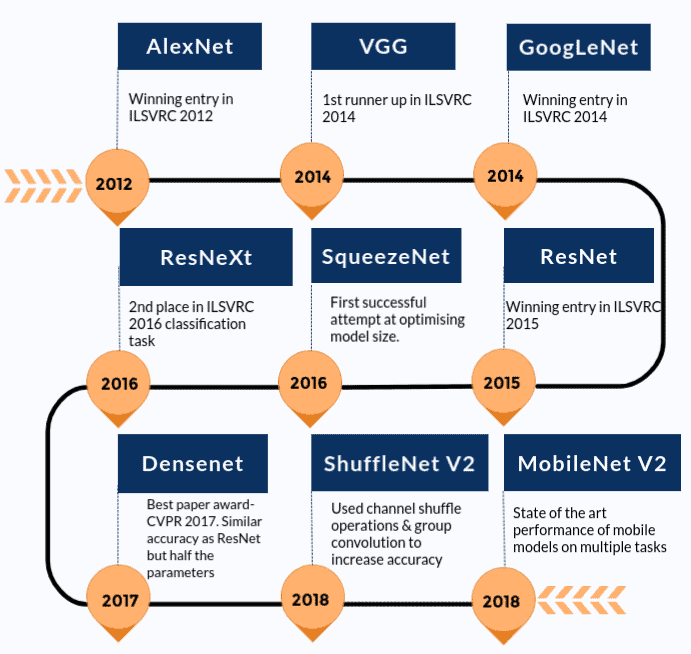
结论:从目前的state-of-art 网络结构看,可以说过 densenet 进行训练:跟resnet 效果相似,但使用的parameter 只有一半。
-
使用多张卡
可以考虑使用多张卡进行训练。(可以使用的卡,并不一定是连续的,这就非常的蛋疼,所以这个功能需要尝试一下)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# Whether to train on a gpu
train_on_gpu = cuda.is_available()
print(f'Train on gpu: {train_on_gpu}')
# Number of gpus
if train_on_gpu:
gpu_count = cuda.device_count()
print(f'{gpu_count} gpus detected.')
if gpu_count > 1:
multi_gpu = True
else:
multi_gpu = False
if train_on_gpu:
model = model.to('cuda')
if multi_gpu:
model = nn.DataParallel(model)
|
-
查看 model 信息
网络结构和参数(是否trainable,是否将weights 进行fixed)
增加了两层的linear
这个时候应该设置最后的 fully connect layer了。将fc 换成一个 nn.Sequential() 这样的layer
(n_inputs =1000, 是imagenet 的数据集)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from torchvision import models
model = models.resnet50(pretrained=True)
# Freeze model weights
# 设置grad 是false
for param in model.parameters():
param.requires_grad = False
n_inputs = model.fc.in_features
model.fc = nn.Sequential(
nn.Linear(n_inputs, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, n_classes),
nn.LogSoftmax(dim=1))
|
device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
设置是否可以trainable
1
2
3
4
5
6
7
|
from torchvision import models
model = models.resnet50(pretrained=True)
# Freeze model weights
# 设置grad 是false
for param in model.parameters():
param.requires_grad = False
|
统计model trainable 的参数量
1
2
3
4
|
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
|
-
选择激活函数
[转载]Pytorch详解NLLLoss和CrossEntropyLoss
对比一下这两个loss function的使用场景,选择一个就行。
-
train 的 optimizer 和 lr_scheduler
可以将learning rate给plot 出来
(对于learning rate )的刻画是很重要的维度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
def plot_lr_finder(lrs, losses, skip_start = 5, skip_end = 5):
if skip_end == 0:
lrs = lrs[skip_start:]
losses = losses[skip_start:]
else:
lrs = lrs[skip_start:-skip_end]
losses = losses[skip_start:-skip_end]
fig = plt.figure(figsize = (16,8))
ax = fig.add_subplot(1,1,1)
ax.plot(lrs, losses)
ax.set_xscale('log')
ax.set_xlabel('Learning rate')
ax.set_ylabel('Loss')
ax.grid(True, 'both', 'x')
plt.show()
|
- 选择不同的model
efficientnet模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import efficientnet_pytorch
from efficientnet_pytorch import EfficientNet
class EfficientNet(nn.Module):
def __init__(self, num_classes):
super(EfficientNet, self).__init__()
self.base = efficientnet_pytorch.EfficientNet.from_name(f'efficientnet-b0')
self.base.load_state_dict(torch.load('../input/modelfnb0/efficientnet-b0-355c32eb.pth'))
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.output_filter = self.base._fc.in_features
self.classifier = nn.Linear(self.output_filter, num_classes)
def forward(self, x):
x = self.base.extract_features(x)
x = self.avg_pool(x).squeeze(-1).squeeze(-1)
x = self.classifier(x)
return x
# class这样进行调用
model = EfficientNet(num_classes=num_classes)
if(accelerator_type == 'TPU'):
model = model.to(device)
else:
model = model.cuda()
|
目前可以参考Transfer Learning with PyTorch进行densetnet 的训练
1
2
3
4
|
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#pretrained=True will download a pretrained network for us
model = models.densenet121(pretrained=True)
model
|
参考PyTorch EfficientNet
使用以下的指标表示运算量:
floating point operations per second (FLOPS, flops or flop/s) i
最简单的引入 efficientnet 的方式
1
2
3
4
5
6
7
8
9
|
from efficientnet_pytorch import EfficientNet
model = EfficientNet.from_name('efficientnet-b1')
# Unfreeze model weights
for param in model.parameters():
param.requires_grad = True
num_ftrs = model._fc.in_features
model._fc = nn.Linear(num_ftrs, 1)
model = model.to('cuda')
|
总结:efficientnet 引入pretrained model 的两种方式:from_pretrained 调用了from_name ,前者的参数设置更全。(ps 你是可以在大类别上训练model 之后,然后在小类别上 finetune的)
1
2
3
4
5
6
7
8
|
@classmethod
def from_pretrained(cls, model_name, weights_path=None, advprop=False,
in_channels=3, num_classes=1000, **override_params):
@classmethod
def from_name(cls, model_name, in_channels=3, **override_params):
"""create an efficientnet model according to name.
|
- with logits 的区别
binary_cross_entropy和binary_cross_entropy_with_logits都是来自torch.nn.functional的函数
有一个(类)损失函数名字中带了with_logits. 而这里的logits指的是,该损失函数已经内部自带了计算logit的操作,无需在传入给这个loss函数之前手动使用sigmoid/softmax将之前网络的输入映射到[0,1]之间
function with logits:
This loss combines a Sigmoid layer and the BCELoss in one single class. This version is more numerically stable than using a plain Sigmoid followed by a BCELoss as, by combining the operations into one layer, we take advantage of the log-sum-exp trick for numerical stability.
意思是将sigmoid层和binaray_cross_entropy合在一起计算比分开依次计算有更好的数值稳定性,这主要是运用了log-sum-exp技巧。
其他
- 随机数的设置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# 版本一
SEED = 1234
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
# 版本二
# Seed everything to avoid non-determinism.
def seed_everything(seed=2020):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
seed_everything()
# 版本三
def fix_randomness(seed):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
fix_randomness(1)
|
- 程序计时
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
# 给出了一个example的调用
best_valid_loss = float('inf')
for epoch in range(EPOCHS):
start_time = time.monotonic()
train_loss, train_acc_1, train_acc_5 = train(model, train_iterator, optimizer, criterion, scheduler, device)
valid_loss, valid_acc_1, valid_acc_5 = evaluate(model, valid_iterator, criterion, device)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut5-model.pt')
end_time = time.monotonic()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc @1: {train_acc_1*100:6.2f}% | ' \
f'Train Acc @5: {train_acc_5*100:6.2f}%')
print(f'\tValid Loss: {valid_loss:.3f} | Valid Acc @1: {valid_acc_1*100:6.2f}% | ' \
f'Valid Acc @5: {valid_acc_5*100:6.2f}%')
|
- Confusion matrix
修改的点:加上横轴和纵轴、每个小格子加上数值、显示出颜色。
1
2
3
|
confusion_matrix_df = pd.DataFrame(confusion_matrix(y_test, y_pred_list)).rename(columns=idx2class, index=idx2class)
sns.heatmap(confusion_matrix_df, annot=True)
|

Efficient:0 需要显存:
4289MiB
Efficient:7 需要显存:
16G 要多一点
Efficient:6 需要显存
14455MiB
efficient:5 需要显存
策略是:使用0 debug 程序,然后使用5 或者6 进行train model。
(重要功能)
需要新增上你的 trainable参数量; 这样可以说明你模型的大小。