Pix2pixhd
文章目录
介绍 pix2pixHD 论文,AED20K 数据集和CoCosNet 数据集。
Pix2PixHD
在这个工作中,我们通过一个新的对抗损失,新的多尺度生成器和判别器架构,来生成2048x1024的吸引人的结果。
首先,我们合并了物体的实例分割信息,它支持对物体的操作,例如删除/添加对象和更改对象类别。此外,我们提出了一种方法,在相同的输入条件下生成不同的结果,支持用户交互式地更改物体外观。
方法
主功能是一个coarse to fine的过程。分为三个部分:coarse-to-fine generator, multi-scale discriminators, improved adversarial loss。
- coarse-to-fine generator
生成器由两个子网络G1和G2组成,其中G1是全局生成器,G2是局部增强生成器。训练过程中,先训练G1,后训练G2,再一起fine-tune。
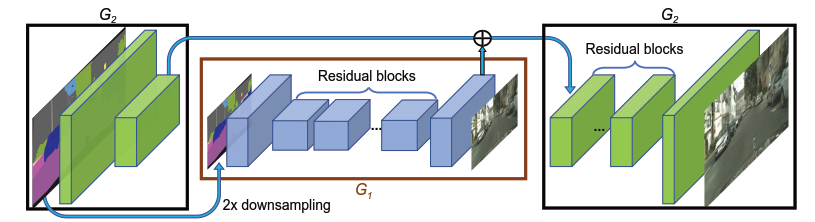
- multi-scale discriminators
使用多尺度判别器做高分辨率判别器,即3个相同网络架构但处理图像尺寸不同的判别器。处理图像的尺寸分别是20481024,1024512,512*256。训练时分别用三种尺度的真假图像训练判别器。 其中,处理coarsest尺度的判别器有最大的感受野,更全局的视野,能使生成器生成全局一致(连续)的图像。处理finest尺度的判别器能使得生成器产生更精细的细节。
- multi-scale discriminators
ADE20K 数据集是用来做场景解析的一个非常大的数据集,包含 150 种物体类型,于 2017 年由 MIT CSAIL 研究组(麻省理工学院 CSAIL 研究组)发布并维护,可用于场景感知、解析、分割、多物体识别和语义理解。
相关论文为 Scene Parsing through ADE20K Dataset;Semantic Understanding of Scenes through ADE20K Dataset。
两个输入
- 实例边界图(instance boundary map)
原理:提出实例图中最重要的信息是物体边界,因此计算实例边界图(instance boundary map)。 计算方法:一个像素点与周围四个像素标签全部相同则赋值0,否则赋值1。即边界处为1,物体内部为0。 具体实现:实例边界图和语义标签图(原输入)的one-hot vector表示串联,输入生成器。同样,判别器的输入是实例边界图、语义标签图和真假图像这三者的通道级串联。 效果:加入实例边界图的模型能生成更真实的物体边界。
Instance Maps 作輔助(Cityscapes資料集有提供)
以往的影像合成方法都只透過 Semantic segmentation label 就生成影像, 但只是依靠 Semantic segmentation 获得的信息有限。如果两个
下面说明 Semantic segmentation 和 instance segmentation 的差别。

Semantic segmentation 表示语义分解(是一个意思就可以划分成一个类别) instance segmentation 是在语义分解的基础上,如果是同一类别的多个物体,那么也是会划分开来,这样能给出更多的detail 信息。
当我们加入了 instance map 之后就能得到物体的边界,明白物体的位置。所以在训练的过程中 是原有的channel 数 + (boundary map) 一起作为输入的

以往的图像使用 latent-code 来改变物体的输出,latent-code 学习的是整张图(一部分)的颜色或者纹理的变化,而不是基于单个物体进行改变。所以作者自行提出了加入一个低维度的 feature 当做输入来改变。实际训练的时候就是使用一个 encoder layer 来获得feature maps,並且對每個物件的 pixel 位置做 average pooling 並且填回去原本的位置,即为 Instance-wise average pooling。比如下图中不同的颜色分别表示不同的物体。

透過這種方式我們就多了 Feature map 可以來控制每個物件的外觀等等。
所以最终的输入是:
原有的 Channel 數 + 1(Boundary map)+ 3(Features : 實驗設定為3層) 一起輸入
在G 网络的输入中,除了 original image, boundary map 之外,还设有low-dimensional feature。为了生成 low-dimensional feature, 作者又设计了一个标准的 encoder-decoder 来生成。在encoder 训练好之后,还使用生成的特征做了一个聚类,从而可以控制生成图像的style。
生成图像的结果:使用boundary map 可以更加精细,对于边缘的处理上给出了比较理想的解决方案。
主要model
https://github.com/NVIDIA/pix2pixHD/blob/master/models/pix2pixHD_model.py
config1(base + generator)
https://github.com/NVIDIA/pix2pixHD/blob/master/options/base_options.py
config2(training + discriminator)
https://github.com/NVIDIA/pix2pixHD/blob/master/options/train_options.py
参考文献
pix2pixHD簡介 - High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs
AED20K 数据集
ADE20k拥有超过25,000张图像(20ktrain,2k val,3ktest)
一些类别可以既是目标,也是部件。例如,一个「门」可以是一个目标(在一张室内图片中)或者一个部件(当它是车的一个门时)。一些目标经常是部件(比如一条腿、一只手),尽管在某些情况下它们看起来与整体是相互独立的(比如车库中的汽车轮子);而有些目标则永远不是部件(比如一个人,一辆卡车等等)。依据于部件所属的目标,相同的名称类别(比如门)可对应于若干个视觉范畴。例如,一个汽车的门从视觉上看是不同于一个橱柜的门的。然而它们也共享一些相似的可供性(affordance)。proportionClassIsPart(c) 的值可以用来决定一个分类是否主要作为一个目标或一个部件。当目标不是另一个目标的一个部件时,其分割掩码将出现在 * _seg.png 内。如果分类是一个部件,则分割掩码将出现在 * _seg_parts.png 内。正确检测目标需要区分目标是否表现为独立目标,或者是否是另一目标的一个部件。
在训练集中:
图像的中值长宽比为 4/3。
图像中值大小为 307200 像素。平均图像大小为 1.3M 像素。
物体分类数量150 发布时间2017年 发布者MIT CSAIL 研究组 适用场景场景感知、解析、分割、多物体识别和语义理解
ADE20K 数据集官网: https://groups.csail.mit.edu/vision/datasets/ADE20K/
ADE20K 在线查看: http://groups.csail.mit.edu/vision/datasets/ADE20K/browse.php/?dirname=/
可以搜索的交互查看界面: http://groups.csail.mit.edu/vision/datasets/ADE20K/dataset_browser/
Understanding Mask R-CNN
Mask R-CNN is basically an extension of Faster R-CNN. Faster R-CNN is widely used for object detection tasks. For a given image, it returns the class label and bounding box coordinates for each object in the image. So, let’s say you pass the following image:
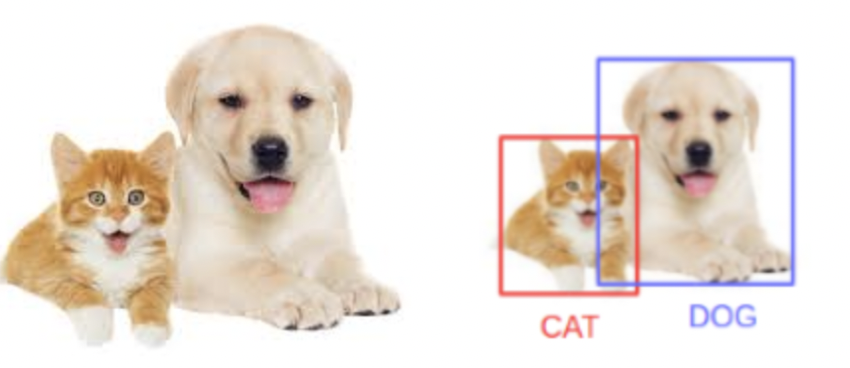
The Mask R-CNN framework is built on top of Faster R-CNN. So, for a given image, Mask R-CNN, in addition to the class label and bounding box coordinates for each object, will also return the object mask.(上图的左半部分是原图,右半部分是结果图)
Facebook AI Research (FAIR) 这个缩写真的是比较nice
CoCosNet
这个是 image edition 最新的研究成果。
issues 中的问题
How to use your model train or test other dataset?
- training resolution is 256x256
- .different datsets may have domain gap, which makes model perform differently. But you can try it
Domain alignment loss before channel-wise normalization
每次在train 的时候, 尽可能使用最新的代码code, 这样作者可能修改一些bug
|
|
we use attention model to get more globel feature to help synthesis. you can get more information in this paper https://arxiv.org/pdf/1711.07971.pdf 关于attention 机制的使用
这里比较详细的说明了 makeup 是如何实现的
Error when running Celebahq (edge-to-face)
这里给出了一个bug,然后通过修改代码解决了
文章作者 jijeng
上次更新 2020-01-28