ProGAN & StyleGAN & StyleGAN2
文章目录
阅读论文– 关于GAN 的一篇综述;介绍对比 ProGAN & StyleGAN & StyleGAN2。
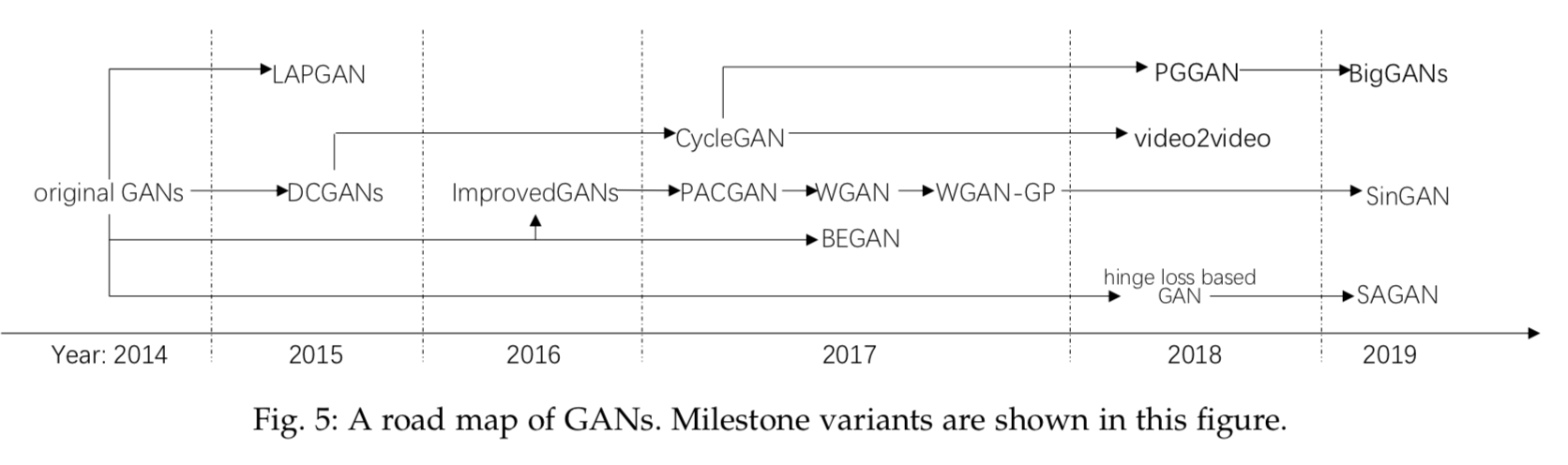
GAN 综述论文
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
Generative algorithms and discriminative algorithms are two categories of machine learning algorithms. If a machine learning algorithm is based on a fully probabilistic model of the observed data, this algorithm is generative.
关于 GANs 的training
One difficulty is from the fact that optimal weights for GANs correspond to saddle points, and not minimizers, of the loss function. 是不是说最优点是在鞍点(G 网络不能辨雌雄),具体需要分析一下 Loss 是如何变化?
ProGAN
In Progressive GAN (PGGAN) , a new training methodology for GAN is proposed. The structure of Progressive GAN is based on progressive neural networks that is first proposed in . The key idea of Progressive GAN is to grow both the generator and discriminator progressively: starting from a low resolution, adding new layers that model increasingly fine details as training progresses.
BigGANs successfully generates images with quite high resolution up to 512 by 512 pixels. If you do not have enough data, it can be a challenging task to replicate the BigGANs results from scratch. Lucic et al. [199] propose to train BigGANs quality model with fewer labels. BigBiGAN [200], based on BigGANs, extends it to representation learn- ing by adding an encoder and modifying the discriminator. BigBiGAN achieve the state of the art in both unsupervised representation learning on ImageNet and unconditional image generation.
创新点:
NVIDIA在2017年提出的ProGAN解决了生成高分辨率图像(如1024×1024)的问题。ProGAN的关键创新之处在于渐进式训练——从训练分辨率非常低的图像(如4×4)的生成器和判别器开始,每次都增加一个更高的分辨率层。
存在的问题:
ProGAN生成高质量的图像,但与大多数模型一样,它控制所生成图像的特定特征的能力非常有限。换句话说,这些特性是互相关联的,因此尝试调整一下输入,即使是一点儿,通常也会同时影响多个特性。一个很好的类比就是基因组,在其中改变一个基因可能影响多个特性。
BigGAN
paper: Large Scale GAN Training for High Fidelity Natural Image Synthesis
丰富的背景和纹理图像的生成是各类生成模型追求的终极目标,ImageNet 的生成已然成为检验生成模型好坏的一个指标。
(1) batch size: 2048 (平时训练时候的 batch 是不是 64 居多), 参数量接近 16 亿;通过 2-4 倍的增加参数量(增加channel )
(2) “截断技巧”:对于先验分布一般选择标准正太分布 $N(0, 1)$ 或者均匀分布 $U[-1, 1]$, 但是作者认为别的分布也是 ok的,所以对经典先验分布进行了截断。(选择的还是标准正太分布)
- 所以为截断机器阿婆是通过对先验分布 z 采样,通过设置阈值的方式截断 z 的采样,其中超出值被重新采样。这个阈值可以根据生成质量指标 IS 和 FID 来决定。
- 设置阈值之后,采样范围变窄,造成生成上取向单一,多样性不足。往往 IS 可以反应图像的生成质量, FID 则更加注重生成的多样性。(IS inception score 越大越好, FID frechet inception distance 越小越好)
- 其他一些稳定训练的 tricks
作者自述: 使用 google 512 块 tpu 进行训练。
从ProGAN 到 StyleGAN
StyleGAN 生成的图像非常逼真,它是一步一步地生成人工的图像,从非常低的分辨率开始,一直到高分辨率(1024×1024)。通过分别地修改网络中每个级别的输入,它可以控制在该级别中所表示的视觉特征,从粗糙的特征(姿势、面部形状)到精细的细节(头发颜色),而不会影响其它的级别。
StyleGAN’s generator is a really high-quality generator for other generation tasks like generating faces. It is particular exciting because it allows to separate different factors such as hair, age and sex that are involved in controlling the appearance of the final example and we can then control them separately from each other. StyleGAN [37] has also been used in such as generating high-resolution fashion model images wearing custom outfits [201]. stylegan 能够把不同的factor 分割开来,然后生成图像。
从 StyleGAN 到 StyleGAN2
改进点包括:
- 提出了替代 ProGAN 的新方法,牙齿、眼睛等细节更完美
- 改善了 Style-mixing
- 更加平滑的插值(额外的正则化)
(1)问题:斑点似的伪影(artifacts)问题
StyleGAN 生成的大多数图像都有类似水滴的斑状伪影。如下图所示,即使当水滴在最终图像中并不明显时,它也会出现在生成器的中间特征图中。这种异常在大约 64×64 分辨率时开始出现,并会出现在所有特征图中,还会在分辨率增高时逐渐变强。这种总是存在的伪影很令人困惑,因为判别器本应该有检测它的能力的。

更多前后效果展示可以查看 这里
可能的原因和解决思路
原因一:
首先,我们研究了常见的斑点状artifacts的起源,并发现生成器创建它们是为了规避其架构中的设计缺陷。我们重新设计了生成器中使用的normalization,从而删除了artifacts。把归一化拿掉或者采用 lazy regularization 的方式,那么水滴就消失了。
使用 Adaptive Instance Normalization (来自于 Style Transfer)
(2)问题: 五官的姿态不同步
StyleGAN 是采用的渐进增大(Progressive Growing)的训练方式。从 4* 4 图像开始,然后到 8* 8,到16 *16,一步步增大生成图像的分辨率,最后形成了1024* 1024. Progressive growing已被证明在稳定高分辨率图像合成方面非常成功。关键问题在于,渐进式增长的生成器在细节上似乎有很强的位置偏好,例如,当牙齿或眼睛等特征在图像上平滑移动时,它们可能会停留在原来的位置,然后跳到下一个首选位置。
 (虽然脸发生了旋转,但是牙齿并没有及时跟着走)
(虽然脸发生了旋转,但是牙齿并没有及时跟着走)
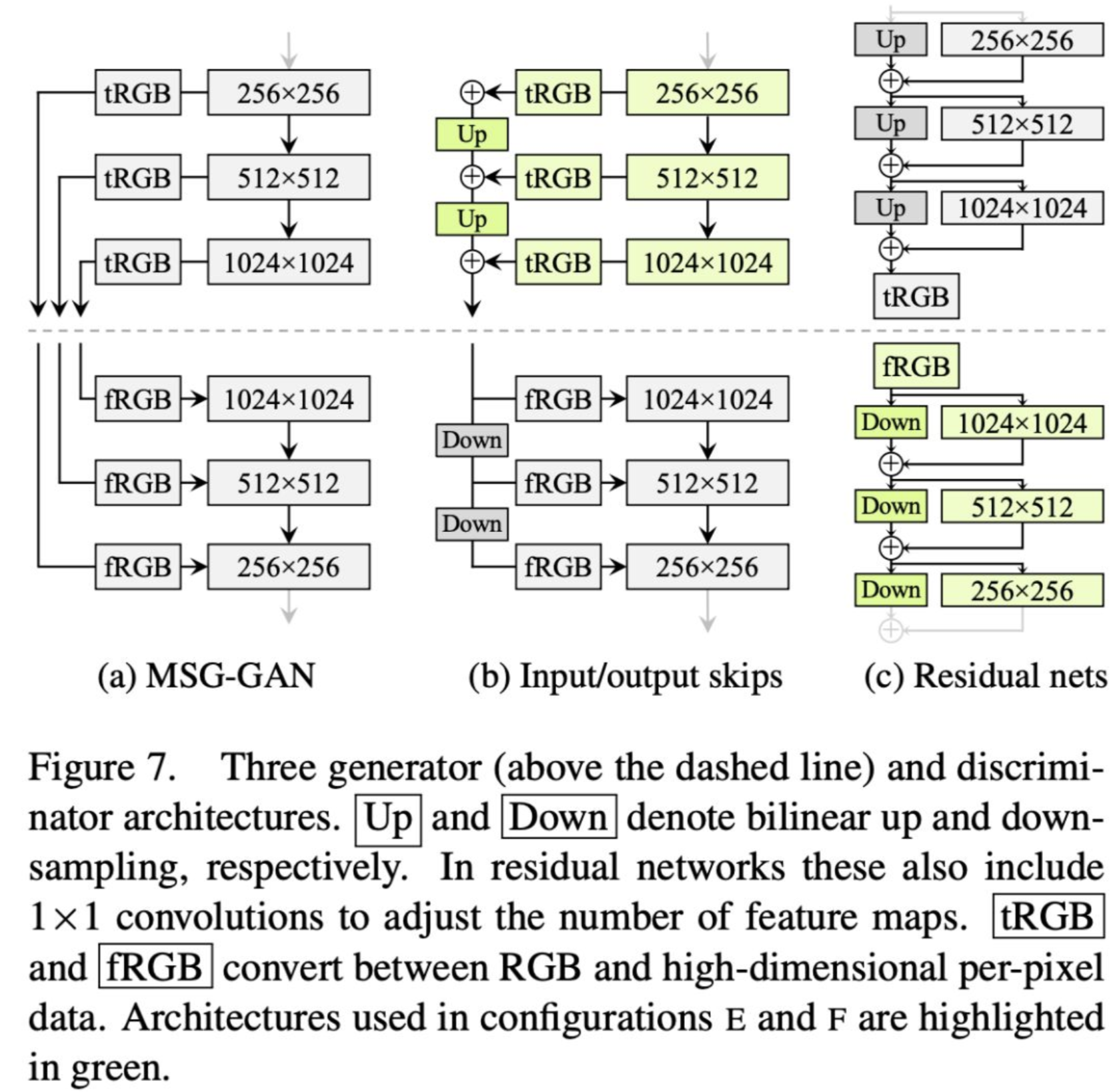
为了解决这些问题,我们提出一种替代的方法,在保留progressive growing优势的同时消除了缺陷。下图a展示了MSG-GAN[22],它使用多个skip connections连接生成器和鉴别器的匹配分辨率。下图b中,我们通过对不同分辨率对应的RGB输出进行向上采样和求和来简化这种设计。在鉴别器中,我们同样向鉴别器的每个分辨率块提供下采样图像。我们在所有上采样和下采样操作中都使用了双线性滤波。下图c中,我们进一步修改了设计,以使用残差连接。这种设计类似于LAPGAN。
一句话总结:Removing Progressive Growing,然后使用上采样和下采样去处理这个问题。
(3)一些小的启发
- 提出了一个新的指标 PPL FID和P&R都基于分类器网络,最近的研究表明,分类器网络侧重于纹理而不是形状,因此,这些指标不能准确地代表图像质量的所有方面。所以提出了一个新的指标:感知路径长度(PPL),用来量化从隐空间到输出图像的映射的平滑度。至于为什么,这一点并不直接和明显。猜想是该指标能够惩罚快速变化的隐藏空间。计算过程中涉及到正则化计算成本比较高,所以作者提出了懒惰式正则化(lazy regularization)。
- 使用了斜坡下降噪声优化了生成器的随机噪声输入
- Deepfake Detection via Projection 这种思路的来源是 kaggle 比赛中,有人通过将图像projection 之后可以有效发现图像是来自GAN网络生成还是真实的图像。
结果:
训练速度更快
生成的图像的质量更高(FID 分数更高, ~3%的提升 ,artifacts 减少)

(4) 损失函数
作为一篇很好的对比性质的论文(项目),loss 函数中提供了很多种类的loss 可供选择。 默认 config-e 和config-f 是下面的loss
D 网络的loss
|
|
G 网络的loss
|
|
StyleGAN-ade

GAN 的训练也可以几k 的数据量上进行训练,那么这个将会便得很亲民。之前都是在百万数据集上进行实验。
主要从数据增强角度来弥补数据量的缺失。

数据增强方式可能会带来 data leak,但并不是所有的数据增强都会,这个论文就是枚举哪些数据增强会,哪些不会。
实验结果

这个原始的数据集只有 900 多张,然后随机 crop 出来一些,组成了 3-4 k 的数据集,左边是最后生成的效果,看起来已经非常不错了。
pixel blitting (像素块传输)
- x-flip
- 90 rotation
- integer translation (这个不是很懂)
general geometric translations
- isotropic scaling
- arbitrary rotation
- anisotropic scaling
- fractional translation
color transformations
- brightness
- contrast
- luma flip (Householder transformation ) 灰阶值
- hue rotation (渐变色)
- saturation (饱和度)

image-space filtering (尺度空间滤波)
- frequency
image-space corruptions
- additive RGB noise
- Cutout

non-leaking augmentations
The goal of GAN training is to find a generator function G whose output probability distribution x (under suitable stochastic input) matches a given target distribution y.
When augmenting both the dataset and the generator output, the key safety priciple is that if x and y do not match, then their augmented versions must not match either.
这个是是否选择该 augmentation 的原则。如果 x 和G网络的输出 经过同样的 augmentation,那么处于同样的分布,那么就被定义为 leaking augmentation,所以就不能被选用。
CycleGAN 学习讲解
主要点在于 : cycle consistency loss
来自论文: Unpaired Image-to-Image Translation
数据方面

loss function

Each generator model is optimized via the combination of four outputs with four loss functions:
- Adversarial loss (L2 or mean squared error).
- Identity loss (L1 or mean absolute error).
- Forward cycle loss (L1 or mean absolute error).
- Backward cycle loss (L1 or mean absolute error).
(感觉图像生成中的 loss function 还是挺多的)
效果图

优缺点
在 color and texture 方面,是比较成功的;但是在 geometric changes (几何)出现了比较多的 failure cases.
如果有 pair 数据,那么可以参考这篇论文: Image-to-Image Translation with Conditional Adversarial Networks
如果有時間可以看一下 pix2pix 的論文,這兩個是側重不同的點。一個是 pair image, 一個是 unpaired image。
CUT (contrastive unpaired translation)
We propose a straightforward method for doing so – maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives.
对比学习, image patch 训练方法(patch-wise fasion)

while content is preserved using cycle-consistency [89,81,37]. However, cycle-consistency assumes that the relationship between the two domains is a bijection, which is often too restrictive.
对比 CycleGAN,cycleGAN 通过 cycle-consistency 确实得到很好的图像,但这种约束相对看来也是比较强的。
Contrastive learning has been an effective tool in unsupervised visual representation learning [9,24,57,80].
对比学习是一种重要的无监督学习方法
MLP 网络结构是需要在代码中看的
multi-layer perceptron 多层次感知
For single image translation, we use a StyelGAN2-based generator [36].
我感觉是可以多试试这种 single image translation 的,因为是很有前景,并且 styleGAN2 应该是不错的。通过跑出来的结果看,并没有跑成论文中的结果。
损失函数
Adversarial loss $$ \begin{equation} \mathcal{L}{\mathrm{GAN}}(G, D, X, Y)=\mathbb{E}{\boldsymbol{y} \sim Y} \log D(\boldsymbol{y})+\mathbb{E}_{\boldsymbol{x} \sim X} \log (1-D(G(\boldsymbol{x}))) \end{equation} $$
Patchwise Contrastive Loss

$$ \begin{equation} \mathcal{L}{\mathrm{PatchNCE}}(G, H, X)=\mathbb{E}{\boldsymbol{x} \sim X} \sum_{l=1}^{L} \sum_{s=1}^{S_{l}} \ell\left(\hat{\boldsymbol{z}}_{l}^{s}, \boldsymbol{z}_{l}^{s}, \boldsymbol{z}_{l}^{S \backslash s}\right) \end{equation} $$
$$ \begin{equation} \mathcal{L}{\text {external }}(G, H, X)=\mathbb{E}{\boldsymbol{x} \sim X, \tilde{\boldsymbol{z}} \sim Z^{-}} \sum_{l=1}^{L} \sum_{s=1}^{S_{l}} \ell\left(\hat{\boldsymbol{z}}_{l}^{s}, \boldsymbol{z}_{l}^{s}, \tilde{\boldsymbol{z}}_{l}\right) \end{equation} $$
$$ \begin{equation} \mathcal{L}{\mathrm{GAN}}(G, D, X, Y)+\lambda{X} \mathcal{L}{\mathrm{PatchNCE}}(G, H, X)+\lambda{Y} \mathcal{L}_{\mathrm{PatchNCE}}(G, H, Y) \end{equation} $$
Pix2pix 学习笔记
在最開始的 GAN 設計中,輸入是隨機噪聲,輸出是一副隨機圖像。目前有三個進展(很老)
- pix2pix: 使用成對的數據 (paired data)
- CycleGAN: 使用 unpaired data 進行訓練
- pix2pixHD: 生成高分辨率、高質量的圖像
pix2pix 對傳統的 GAN 做了修改,不再輸入隨機噪聲,而是用戶輸入的图像。另外,为了学习 pair data 的关系,作者把 G的输入和输出一起作为 D 的输入(可以对比一下原始的 GAN 的损失函数)

Training Generative Adversarial Networks in One Stage
GitHub:https://github.com/zju-vipa/OSGAN
intuition

intuition
方法

这个是网络结构

最后生成的效果
评价:效果很一般。pass
实验环境
运行环境
- 显卡:官网要求有16GB内存的NVIDIA GPU(即:NVIDIA 特斯拉 Tesla V100),经实测,11GB内存的NVIDIA GeForce RTX 2080Ti也可以跑起来。如果只是简单的跑跑别人训练好的例子,那么使用配置比较低的也可以,但是训练的话,那么得使用比较高的配置。
- 版本:使用 TensorFlow 1.14 而不要使用 TensorFlow 1.15; linux 环境
kaggle 中GAN生成图像的总结
比较好的代码
{% fold 开/合 %}
- 图像预处理和数据增强
|
|
- Crop images using bounding box
想说的是,如果有了标注(bounding box),那么这个是可以做到更加精确,至少在数据预处理部分。
|
|
(3)第三种对于数据的处理, Conditional ProGan
Transforms
- RandomHorizontalFlip, p=0.5
- CenterCrop or RandomCrop
- A bit of ColorJitter
- Rescale between [-1, 1]
Rotating is not used, and I also tried other normalization methods.
(4) 在jupyter 中随机展示图像的技术,还是比较好的
|
|
如何去判断 GAN 已经过拟合了?如果过拟合了(可以使用数据增强,但是对于gan 如何去判断过拟合了呢?)
Data Augmentation help in training model better. Its like increasing size of your Dataset and prevents overfitting.
Crops will give be having only dogs in them, so model will be able to learn better and easier.
|
|
在pytorch 中固定 seed
|
|
使用长宽比例进行筛选图像, SUB of RaLSGAN-improved-parameters-ram-64
|
|
|
|
{% endfold %}
图像数据预处理
The blue rectangles are the provided bounding boxes. I cropped all images to the yellow squares and resized them to 80x80 pixels. I chose a square that captures my best guess of where the dog head is and added padding beyond the bounding box to allow for random cropping during training. 如果你最后使用 64 *64 去跑实验,那么先resize 成80 *80,这样是是可以之后进行数据增强的。(很好的tips)
Data Augmentation, Random Cropping Each original image was cropped to a 80x80 square that included 25% extra image beyond bounding box (yellow squares below). This extra room allows us to randomly choose a 64x64 crop within (red squares below) and mostly stay outside the bounding box (blue rectangles). 上面的一步是为了下面的步骤做准备

使用上面两个步骤得到的图像如下。

三种图像的预处理:
image processing a) bounding box cropping only; b) bounding box cropping for images with multiple objects, for images with single object and boxsize / imagesize >= 0.75, use original images instead of bounding box. c) bounding box cropping plus all original images
Among the three processing methods, b) gets me the best private score, c) gets me the best public score 18, but did not go well with the private dataset. 如果有了 bounding box,那么最后的结果是是更好的的。
常见的可能需要调整的超参数
losses I experimented with losses such as “standard-dcgan”, “wgan-gp”, “lsgan”, “lsgan-with-sigmoid”, “hinge”, “relative-hinge”. My experience is the best one for this problem with various models is the “standard dcgan” loss, the second best is “lsgan-with-sigmoid” loss.
Attention at different stages According to the paper “Self-Attention Generative Adversarial Networks”(https://arxiv.org/pdf/1805.08318v2.pdf), self-attention at middle-to-high level feature maps achieve better performance because it receives more evidence and more freedom to choose conditions with larger feature maps. My experiences mostly concur with the paper findings. I have attention at 32x32 feature map for the generator, but at 16x16 feature map for the discriminator.
Training settings The learning rate for the discriminator is 0.0004, and the learning rate for the generator is 0.0002; batch size is 32(tried 64 but the result is not as stable as 32); label smoothing; thanks the kernel https://www.kaggle.com/phoenix9032/gan-dogs-starter-24-jul-custom-layers and its author Nirjhar Roy. learning rate scheduler: CosineAnnealingWarmRestarts number of epoch: 170
the best latent space dimension size: 180
8th place solution(private 89)
To be honest, there is no special technique in my solution. I chose stylegan, then looked for good parameters. My stylegan starts with public score 140, then tuning parameters, I got 35.
for preprocessing: crop image by bounding box, random horizontal flip (从道理上讲,水平翻转还是有用的,因为90度翻转可能没有语义信息,但是水平翻转是有点语义的) reduce input channel size of style generator to 256 because of resource limitation. all hyper parameters are shown in below.
stylegan 中的参数好好看:
trials that didn’t work for me Truncation trick from stylegan paper. I tried various truncation strength, but without truncation was the best. Auxiliary Classifier Data cleaning. I thought training data quality is quite important, so I did some procedure (dog face detection, manually picking good images..) but nothing worked. Today, I read some kernels and learned there’s some good techniques. This is one of the room for improvement of my solution, I guess. It was really fun competition! Thanks for kaggle team!!
Truncation trick in W, 这个数字是在0和1 之间,越是接近0,那么最后生成的图像越是趋同;越是接近1,最后的图像越是多样性。
1st place solution
Preprocessing&Augmentations
- exclude images with extreme aspect ratio (y/x < 0.2 and y/x > 4.0)
- exclude images with intruders (thanks @korovai for sharing the kernel https://www.kaggle.com/korovai/dogs-images-intruders-extraction-tf-gan)
- use BoundingBox (no modification)
- Resize 64 (one side) and then RandomCrop to image size (64,64)
- HorizontalFlip(p=0.5 以p=0.5 的概率)
模型和参数相关
・Model: BigGAN
- number of parameters G:10M, D:8M
- input noise from normal distribution (nz=120)
- use LeakyReLU
- attention on size 32 feature map
- use truncated trick (threshold=0.8)
- no EMA
・Loss: BCE loss ・Optimizer: Adam (lrG=3e-4, lrD=3e-4, beta1=0.0, beta2=0.999) ・Batch Size: 32 ・Epochs: 130 (maximum kernel time limit, i.e. 32400sec) ・Others
- label smoothing 0.9
I made my kernel public https://www.kaggle.com/tikutiku/gan-dogs-starter-biggan version32 is the 1st place solution (注意查看的是version 32 )
数据预处理方面
Transforms
-
RandomHorizontalFlip, p=0.5
-
CenterCrop or RandomCrop
-
A bit of ColorJitter
-
Rescale between [-1, 1]
-
I used dog boxes, but enlarge them by 10px on each side (这个的使用,是和上面的 centercrop 和randomcrop 相适应的)
-
Dog races are also used
ColorJitter类也比较常用,主要是修改输入图像的4大参数值:brightness, contrast and saturation,hue,也就是亮度,对比度,饱和度和色度。可以根据注释来合理设置这4个参数。
medalConditional ProGan [30 public]
数据预处理方面
在使用 resize的时候, cv2.INTER_AREA 这个是关键。
|
|
G 网络的noise 是不是也可以使用其他的方式,比如下面的Uniform input noise ?
|
|
FID emphasizes sample diversity too much.
Key points:
Model: based on BigGAN shared embedding of dog breed labels hierarchical latent noise projection auxiliary classifier (ACGAN) Loss: RaLS with weighted auxiliary classification loss Batch size: 128 Exponential Moving Average of generator weights Uniform input noise on real images
数据处理方面
My goal with image transformations at first was to keep as much usefull information as possible. Given how the FID metric is sensitive to missing modes, it’s reasonable to keep most of the images, even the unhandy ones.I focused mostly on geometric transformation. Pixel-level augmentation didn’t bring any improvements for me.
超参数方面
I found it a lot easier to use generator with less parameters than default settings. (使用更加简单的G 网络)
cyclic learning rates with cosine annealing and soft/hard warmups. With some settings it has a positive impact but tend to lack consistency. (learning rate 的调度算法)
other possible z distrubutions as described in the BigGAN paper (Appendix E). Bernoulli didn’t work at all, censored Gaussian gave a bit worse results than usual normal distribution.(z 的分布这个超参数)
|
|
调参部分
大胆去尝试调参!!!
To build a great GAN, you first build two great convolutional networks (Gen and Disc). Use either ResNet (BigGAN) or VGGNet (DCGAN) architecture. Next choose a loss function. Hinge loss is the current favorite. (Others are GAN, RaLSGAN, WGAN, ACGAN, etc) Then to prevent training from exploding, add normalization/regularization such as weight clipping, gradient penalty (WGAN-GP), batch norm, or spectral normalization (SN-GAN), etc. For best performance add modulation via batch norm using either class labels (CGAN), style labels (StyleGAN), or random noise labels (Self Mod). Next optimize your hyperparameters; alpha, beta1 and beta2 of your Adam optimizer. Choose if the discriminator will train extra epochs versus generator. Lastly choose a dataset, add more data with data augmentation, and start training on a fast GPU !
After a few experiments, my BigGAN achieves LB 42 with the following changes from default. Batch size to 32 (from 64), learning rates to Adam alpha=0.0003, beta1=0.2, beta2=0.9 (from 0.0002, 0, 0.9). Discriminator channels to 48 (from 64), generator channels to 48 (from 64), train for 40,000 iterations with exponential decay beginning at 32,000.
11th place solution
这两篇是使用stylegan 进行调参的经验,可以多看看。 https://www.kaggle.com/c/generative-dog-images/discussion/106452 https://www.kaggle.com/c/generative-dog-images/discussion/104281
参考文献
posted in Generative Dog Images
其他:https://github.com/interviewBubble/Data-Science-Competitions
这个给出了一个 ui 界面进行训练的 (这种项目是可以用来作为小作业的,因为是可以展示的)
https://github.com/HyperGAN/HyperGAN
|
|
文章作者 jijeng
上次更新 2020-01-11