伪标签(Pseudo-Label):一种简单有效的半监督学习方式
文章目录
对于伪标签(Pseudo-Label)的学习整理。
半监督学习
我们在解决有监督机器学习(深度学习)中取得了巨大的进步,这个过程需要大量构建训练数据集。但是这并不是人类的学习过程,我们可能需要少量的点,然后就从中总结出规律,俗话说举一反三,对应到机器学习领域,该技术称为半监督学习。所谓的监督就是数据的label,如果学习的过程全部需要label,那么就是有监督学习;如果全部不需要,那就是无监督学习,介于两者之间的是半监督学习。如下图所示。
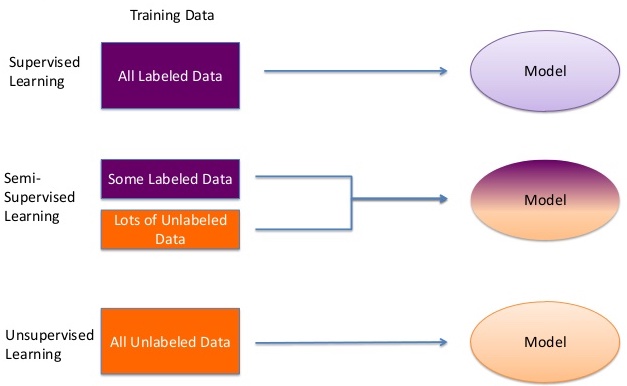
半监督学习方式有很强的现实意义。获取有标注的数据是需要成本和时间,并且有时候并不能获取大量标注数据。相比之下,我们很容易能够收集到大量未标注数据这,所以半监督学习就很有实用价值。使用一部分的标注数据和比较大量的未标注数据就可以学习到模型的模式。

伪标签方式
伪标签方式是一种简单有效的半监督方式(没有说效果最好的方式),首次被该篇论文提出
(Pseudo-labeling was introduced by Lee (2013), so you can find more details there.)
算法步骤
利用训练数据构建模型 预测测试集的标签 将预测的置信度较高的测试集标签和结果加到训练集中 重新在新的合并的数据集上训练模型 利用新的模型预测并提交结果
Take the same model that you used with your training set and that gave you good results. Use it now with your unlabeled test set to predict the outputs ( or pseudo-labels). We don’t know if these predictions are correct, but we do now have quite accurate labels and that’s what we aim in this step. Concatenate the training labels with the test set pseudo labels. Concatenate the features of the training set with the features of the test set. Finally, train the model in the same way you did before with the training set.
Train model on a batch of labeled data Use the trained model to predict labels on a batch of unlabeled data Use the predicted labels to calculate the loss on unlabeled data Combine labeled loss with unlabeled loss and backpropagate …and repeat.
其中loss 函数可以表示为
\begin{equation} L=\frac{1}{n} \sum_{m=1}^{n} \sum_{i=1}^{C} L\left(y_{i}^{m}, f_{i}^{m}\right)+\alpha(t) \frac{1}{n^{\prime}} \sum_{m=1}^{n^{\prime}} \sum_{i=1}^{C} L\left(y_{i}^{\prime m}, f_{i}^{\prime m}\right) \end{equation}
或者简单表示为
$$ loss = label loss + weights * unlabeled loss $$
In the equation, the weight (alpha) is used to control the contribution of unlabeled data to the overall loss. In addition, the weight is a function of time (epochs) and is slowly increased during training. This allows the model to focus more on the labeled data initially when the performance of the classifier can be bad. As the model’s performance increases over time (epochs), the weight increases and the unlabeled loss has more emphasis on the overall loss. 其中公式中的weights 是随着时间(epoch)变化。
\begin{equation} \alpha(t)=\left{\begin{array}{ll}{0} & {t<T_{1}} \ {\frac{t-T_{1}}{T_{2}-T_{1}} \alpha_{f}} & {T_{1} \leq t<T_{2}} \ {\alpha_{f}} & {T_{2} \leq t}\end{array}\right. \end{equation}
变化关系可以汇总为
 (可以理解随着时间增长,unlabeled loss 的权重是变大的)
(可以理解随着时间增长,unlabeled loss 的权重是变大的)
Intuition ( Why does Pseudo-Labeling work?)
- Continuity Assumption (Smoothness): Points that are close to each other are more likely to share a label. (Wikipedia) In other words, small changes in input do not cause large changes in output. This assumption allows pseudo labeling to conclude that small changes in images like rotation, shearing, etc do not change the label.
- Cluster Assumption: The data tend to form discrete clusters, and points in the same cluster are more likely to share a label. This is a special case of the continuity assumption (Wikipedia) Another way to look at this is — the decision boundary between classes lies in the low-density region (doing so helps in generalization — similar to maximum margin classifiers like SVM). 两大假设支撑该理论
This is why the initial labeled data is important — it helps the model learn the underlying cluster structure. When we assign a pseudo label in the code, we are using the cluster structure that the model has learned to infer labels for the unlabeled data. As the training progresses, the learned cluster structure is improved using the unlabeled data. If the initial labeled data is too small in size or contains outliers, pseudo labeling will likely assign incorrect labels to the unlabeled points. The opposite also holds, i.e. pseudo labeling can benefit from a classifier that is already performing well with just the labeled data. 使用该方式的基本条件:有足够()的数据能够比较好描述数据的分布,然后 Pseudo-Labeling 做得是能够使得结果更好;如果初始化很不好,那么最后的结果也不会很好。
常见的问题
But, how can I know the proportion of true labels and pseudo-labels in each batch? In other words, how much do I make it a mix of training vs pseudo? The general rule of thumb is to have 1/4–1/3 of your batches be pseudo-labeled. 搭配比例:一般是需要四分之一到三分之一作为虚假label 存在。 How do I know when to stop changing a model? We still don’t know how to create optimal architectures nor when to stop messing with a model, So just keep trying.
常见的应用场景
实现(Demo未做)
参考文献
Simple explanation of Semi-Supervised Learning and Pseudo Labeling Pseudo-Labeling to deal with small datasets — What, Why & How? Why does using pseudo-labeling non-trivially affect the results?
文章作者 jijeng
上次更新 2020-02-26