在python 中经常遇到以下的概念:容器(container)、可迭代(iterable)、迭代器(iterator)和生成器(generator)。上述概念经常混淆,整理一下,总结为图:
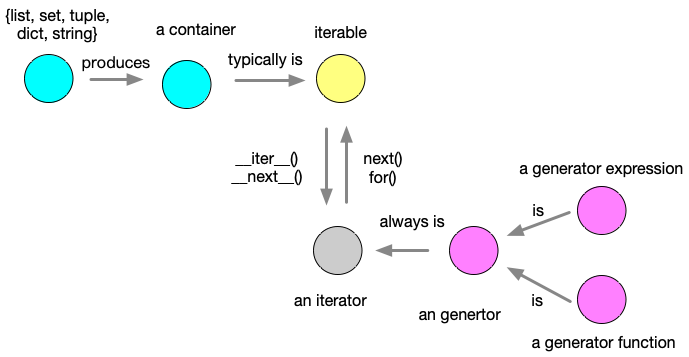
- 容器(container)
容器(container)从字面的意思上很好理解,包含一定数量元素的物体。比如说 list, set, tuple, dictioinary , string等。容器的特点在于数量有限,大多数是可迭代,布隆过滤器(Bloom filter)一般是不可迭代的,因为太大了。
- 可迭代(iterable)
容器大多数是可迭代,但是可迭代的不一定是容器,不一定是某个数据结构,比如按行读取文件,打开一个sockets等操作。容器数据量一般是有限的,但是sockets操作可能是无限的数据量。所以任何物体都有可能满足可迭代性质。
在python 语言,可迭代类需要实现___iter__() 和 __next__() 两个方法。下面的例子使用 Fibonacci数建立一个迭代器。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class fib:
def __init__(self):
self.prev =0
self.cur =1
def __iter__(self):
return self
def __next__(self):
val =self.cur
self.cur += self.prev
self.prev =val
return val
f =fib()
list(islice(f, 0, 10 )) #[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
|
islice 是itertools中切片选择的函数,其中,iterable 是可迭代对象,start 是开始索引,stop 是结束索引,step 是步长,start 和 step 可选。
1
|
islice(iterable, [start,] stop [, step])
|
- 迭代器(iterators)
任何具有__next__() 方法的物体都是迭代器,使用 next()方法或者 for循环可以获取下一个元素。python中的模块 itertools 可以用于构建高效的迭代器。迭代的特点是惰性求值(lazy evaluation),即只要当迭代到该值的时候,才会被计算,非常适合于大文件或者无限集合的遍历,不用一次性存储在内存中。该模块中的迭代器类型分为以下三种:
(1) 无限迭代器
- count(firstval=0, step=1)
创建一个从 firstval (默认值为 0) 开始,以 step (默认值为 1) 为步长的的无限整数迭代器
1
2
3
|
from itertools import count
counter =count(start =13)
next(counter)
|
- cycle(iterable)
对 iterable 中的元素反复执行循环,返回迭代器
1
2
3
4
5
6
|
from itertools import cycle
colors =cycle(['red', 'white', 'blue'])
next(colors) # red
next(colors)
next(colors)
next(colors) # red
|
- repeat(object [,times]
反复生成 object,如果给定 times,则重复次数为 times,否则为无限
(2) 有限迭代器
- chain()
- dropwhile()
- groupby()
chain的使用 (字面意思,将两个相同或者不同的可迭代object 连接起来)
1
2
3
|
from itertools import chain
for item in chain([1, 2, 3], ['a', 'b', 'c']):
print( item)
|
功能:输入是一系列可迭代对象,输出是一个可迭代对象的函数。优点:相比于书写两个循环去处理,使用 chain 关键字更加简洁。
dropwhile的使用
1
|
dropwhile(predicate, iterable)
|
其中,predicate 是函数,iterable 是可迭代对象。对于 iterable 中的元素,如果 predicate(item) 为 true,则丢弃该元素,否则返回该项及所有后续项。(这种逻辑还是比较有意思的,只是进行一次的筛选)
1
2
3
|
from itertools import dropwhile
list(dropwhile(lambda x: x < 5, [1, 3, 6, 2, 1])) #[6, 2, 1]
list(dropwhile(lambda x: x > 3, [2, 1, 6, 5, 4])) #[2, 1, 6, 5, 4]
|
(3) 组合生成器
itertools 模块还提供了多个组合生成器函数,用于求序列的排列、组合等:
- product
- permutations
- combinations
- combinations_with_replacement
product 用于求多个可迭代对象的笛卡尔积,和嵌套的for 循环是等价的
1
2
3
|
from itertools import product
for item in product('ABCD', 'xy'):
print item
|
permutations用于生成一个排列
1
|
permutations(iterable[, r])
|
其中,r 指定生成排列的元素的长度,如果不指定,则默认为可迭代对象的元素长度。
1
2
|
from itertools import permutations
permutations('ABC', 2)
|
combinations用于求序列的组合,它的使用形式如下
1
2
|
from itertools import combinations
list(combinations('ABC', 2))
|
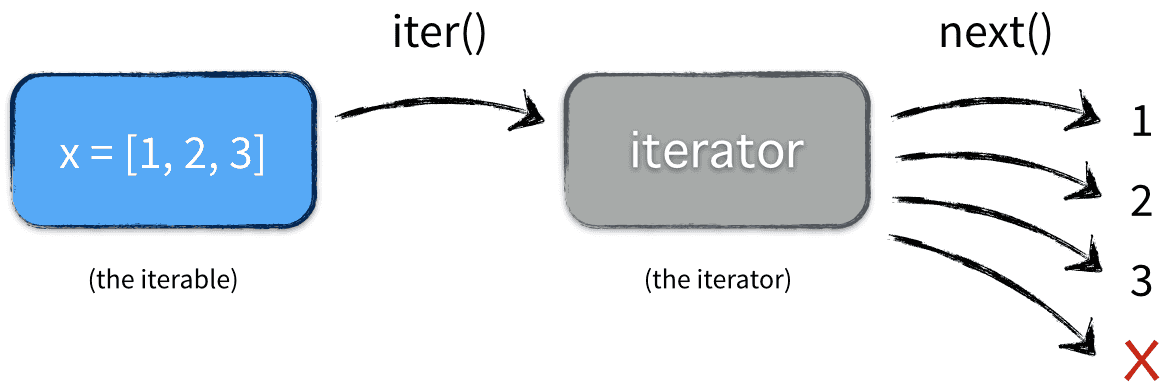
迭代器函数的返回值是迭代器,而不是list。
并且上述容器可以转换成迭代器。
1
2
3
4
|
x =[1, 2, 3]
z =iter(x)
next(z)
next(z)
|
- 生成器(generator)
生成器必然是一种迭代器。写法更加简洁,不用实现__iter__() 和__next__() 方法,需要关键字 yield就ok。还是使用 Fibonacci数作为例子。
1
2
3
4
5
6
7
|
def fib():
pre, cur =0,1
while True:
yield cur
pre, cur =cur, pre+ cur
f =fib()
list(islice(f, 0, 10))
|
有木有代码量骤减的感觉。
在python 中有两种类型的生成器:生成器函数和生成器表达。包含关键字yield 就是生成器函数(如上例子),生成器表达更加简洁,相当于list comprehension。比如
1
2
3
4
5
6
7
8
9
10
11
|
numbers =[1, 2, 3, 4, 5]
# list comprehension
[x*x for x in numbers]
# set comprehension
{x*x for x in numbers}
# or dict comprehension
{x: x*x for x in numbers}
# not a tuple comprehension, 这个是一个 生成器表达
lazy= (x*x for x in numbers) # a generator
next(lazy)
lsit(lazy)
|
在处理训练数据集的时候,从
1
2
3
4
5
|
def something():
res =[]
for ... in ..:
res.append(x)
return res
|
转换成
1
2
3
|
def iter_something():
for ... in ...:
yield x # yield 并没有结束,等待下一个 next()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
numbers = list()
# range()
for i in range(1000):
numbers.append(i + 1)
total = sum(numbers)
# (2) Using a generator
def generate_numbers(n):
num = 0
while num < n:
yield num
# 这个yield 之后,函数并没有结束,不像 return 那种函数
num += 1
total = sum(generate_numbers(1000))
print(total)
total = sum(range(1000 + 1))
print(total)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# generator 的第一种实现 ()
g =(x*x for x in range(10))
print(next(g))
print(next(g))
# 实现一个 image loader
# generator的第二种实现 yield 关键字实现,
def read_data(file1):
f =open(file1)
x =[]
y =[]
while True:
line =f.readline()
if not line: break
line =line.split()
x =line[:-1]
y =line[-1]
y =map(float, y)
data.append(line)
return data
def train_data(file1, batch_size):
train_x, train_y =read_data(file1)
num_batch =len(datas) //batch_size
for i in range(num_batch):
x = train_x[batch_size*i: batch_size*(i+1)]
y =train_y[batch_size*i: batch_size*(i+1)]
yield np.array(x), np.array(y)
next(train_data(file1, batch_size))
|
在 python 中判断一个 object 是否是 iterable
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 比较正式的写法
import collections
if isinstance(obj, collections.Iterable):
# 非正式的写法
try:
_ (e for e in my_object)
except TypeError:
print(my_object, 'is not iterable')
|
参考文献
Iterables vs. Iterators vs. Generators
Bloom filter - Wikipedia