文本相似度比较基本知识(1)
文章目录
互联网网页存在大量的重复内容网页,无论对于搜索引擎的网页去重和过滤、新闻小说等内容网站的内容反盗版和追踪,还是社交媒体等文本去重和聚类,都需要对网页或者文本进行去重和过滤。本文介绍的 Locality Sensitive Hashing 是常见的一类hash 函数用于去重。 SimHash是一种局部敏感hash,它也是Google公司进行海量网页去重使用的主要算法。
Locality Sensitive Hashing
Hash 函数能够保证最后的映射空间唯一性和均匀分布,但是不能保证原来相似向量,映射之后也是相似的。但是局部敏感hash(比如 simhash or minhash )是能够保证这一点的。也可以从降维的角度进行理解,降维之前和降维之后,相似的文档(这里就具体化一个东西)hash 之后也是相似的。
局部敏感哈希的基本思想:在高维数据空间中的两个相邻的数据被映射到低维数据空间中后,将会有很大的概率任然相邻;而原本不相邻的两个数据,在低维空间中也将有很大的概率不相邻。通过这样一映射,我们可以在低维数据空间来寻找相邻的数据点,避免在高维数据空间中寻找,因为在高维空间中会很耗时。有这样性质的哈希映射称为是局部敏感的。simhash 或者minhash是局部敏感hash的一种具体实现。局部敏感哈希是一种思想。
应用:对于高维数据的海量数据近邻查找,局部敏感哈希是一个很好的解决方法。在很多问题中,从海量数据库中寻找到与查询数据相似的数据是一个很关键的问题。可以具体应用到文本相似度检测、网页搜索等领域。
Simhash
我们现在处理的是大数据维度上的文本去重,这就对算法的效率有着很高的要求。但是在小的样本上这个是不一定有保证有效的,小文本使用 NLP 相关知识可能得到更好的精度。SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。本文服务于该篇博客,主要进行名词解释。
基本概念
simhash 也是一种hash,一般的hash 函数映射规则只需要满足以下两个条件:
- 对很多不同的特征来说,它们对所对应的向量是均匀随机分布的
- 相同的特征来说对应的向量是唯一
simhash 和传统的 hash 不同点在于前者的01 串是可以表征文本之间的相似度,而后者是不可以的。
简单来说普通的hash映射需要满足随机分布和唯一性两个条件。simhash想要实现的是,如果原来的文本的特征是相似,那么映射之后的编码也是相似。这里使用 hamming distance 进行比较simhash映射之后的距离。根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。编码之后的表示在英文中是 fingerprint(指纹)。
simhash最初被google 用于网页去重,当时使用的fingerprint 是64,所以这里沿用了这个传统。64位的签名可以表示多达$2^64$个象限,因此只保存所在象限的信息也足够表征一个文档了。 更进一步,表示的文档的数字最多是多少?这个应该可以准确计算特征的个数应为如果用三位(01) 表示,那么有8种,那么2^64 这么多种特征,所以16*10^18 这么多。
算法步骤
Simhash 分为5个步骤:分词、hash(md5 要求均匀映射到某空间就行,不要求反应原始样本的相关性)、加权、合并(列项相加)、降维(正数为1 负数为0),得到每篇文章的simhash 之后,计算两个文章的海明距离(两个字符串对应位置的不同字符的个数)。对于64 位的simhash 值,在3以内就可以认为是比较相似的。

第一步:文本预处理得到分词(去重,去除的了stop words),然后weight权重可以使用分词的frequency 或者tfidf 进行得到 第二步:进行hash 映射(可以使用md5这种传统的映射方式,基本的要求就是均匀映射到一个空间,这种映射并不能反映原始样本的相关性) 第三步:hash 映射值和weight 进行相乘,如果原来是1 则乘以1,如果是0 则乘以-1, 第四步: 列向相加,得到summing weights,进行降维如果是正数那么为1,如果是负数那么为-1 第五步: 计算不同文本之间的 hamming distance。
然后这个simhash就出来了. 有图有真相

simhash的局限性:
只考虑到文章存在哪些词,没有考虑到词的顺序。不过相应的优点是,可以实现海量文章相似度计算。文章相似度计算忽略词的顺序之后效果更好。所以在处理大文本时候,simhash是有效的,但是在处理小文本,这种效果往往不能被保证。直观上理解,在一片段文章或者段落中,词语出现的顺序还是比较重要的。更加准确的说,这个是用来进行判重的算法,而不是计算相似度的算法。
开源实现:
simhash 的实现,调用一个库 https://www.twblogs.net/a/5c178f2cbd9eee5e40bbc9e9/zh-cn
simhash 的一个github https://github.com/yanyiwu/simhash
百度去重: top k 最长的语句,作为源数据
minhash
总的操作步骤如下:

- 对一个文档转化为关键词的集合,用这个集合来表示这个文档,叫Shingling。
- 用MinHashing函数来构造哈希表。
- 使用LSH来寻找相似的文档。
对于第一点中的Shingling,这个k 是一个关键参数,可以体现上下文的那种。 例如:k=2,doc=adcab,这个集合的2-shingles={ab,ba,ca} 。我们对这个字符串进行划分,得到的是ad dc ca ab,由于集合是唯一性的所以不可能有重复的元素。k=2 其实是一个比较糟糕的选择,我们一般选择K在实际情况中一般会选择9或者10,我们要求这个k一般要大于我们文章中出现的单词的长度。这样的选择会比较合理一些。
使用一个具体的例子讲解 minhash 的操作步骤:
第一步:
文档的Shingling:对于中文首先进行分词,得到每篇文章的词语的集合(集合是去重之后的结果),这里是可以做n-gram 的思想的,这个n 的取值越大,越能找到真正相似的文档,代价是dictionary 很大,存储上的
|
|
第二步:
文档的矩阵表示(如果keyword 在相应的文章中出现,标记为1 否则标记为0)
| 元素 | S1 | S2 | S3 | S4 |
|---|---|---|---|---|
| 我 | 1 | 0 | 0 | 1 |
| 他 | 0 | 0 | 1 | 0 |
| 要 | 0 | 1 | 0 | 1 |
| 减肥 | 1 | 0 | 1 | 1 |
| 成功 | 0 | 0 | 1 | 0 |
真正实践中的矩阵应该是十分稀疏的。
第三步:
最小hash定义为:特征矩阵按行进行一个随机的排列后,第一个列值为1的行的行号。举例说明如下,假设之前的特征矩阵按行进行的一个随机排列如下:
| 元素 | S1 | S2 | S3 | S4 |
|---|---|---|---|---|
| 我 | 1 | 0 | 0 | 1 |
| 减肥 | 1 | 0 | 1 | 1 |
| 成功 | 0 | 0 | 1 | 0 |
| 他 | 0 | 0 | 1 | 0 |
| 要 | 0 | 1 | 0 | 1 |
最小哈希值:h(S1)=1,h(S2)=5,h(S3)=2,h(S4)=1.
从图中可以知道,应该从 input matrix(原始的matrix )得到新的 signature matrix。
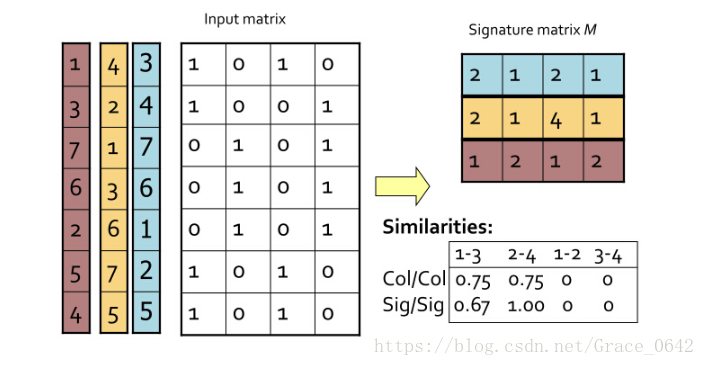
签名的相似性 1/3 ,以此类推我们可以得到我们所求的图中要求的相似性,我们看图中第2列和第3列 Jaccard similarity 就是 1/5,我们签名的相似性就是1/3 。
使用 signature matrix 去近似的表示 Jaccard similarity
这个是第一二列的 input matrix
0 1 0 0 1 0 0 1 0 0 1 1 0 0
这个是signature matrix
3 1 2 2 1 5
为什么使用上述方法是有效?
事实上,两列的最小hash值就是这两列的Jaccard相似度的一个估计,换句话说,两列最小hash值同等的概率与其相似度相等,即P(h(Si)=h(Sj)) = sim(Si,Sj)。为什么会相等?我们考虑Si和Sj这两列,它们所在的行的所有可能结果可以分成如下三类:
(1)A类:两列的值都为1;
(2)B类:其中一列的值为0,另一列的值为1;
(3)C类:两列的值都为0.
特征矩阵相当稀疏,导致大部分的行都属于C类,但只有A、B类行的决定sim(Si,Sj),假定A类行有a个,B类行有b个,那么sim(si,sj)=a/(a+b)。现在我们只需要证明对矩阵行进行随机排列,两个的最小hash值相等的概率P(h(Si)=h(Sj))=a/(a+b),如果我们把C类行都删掉,那么第一行不是A类行就是B类行,如果第一行是A类行那么h(Si)=h(Sj),因此P(h(Si)=h(Sj))=P(删掉C类行后,第一行为A类)=A类行的数目/所有行的数目=a/(a+b),这就是最小hash的神奇之处。
第四步:
这个只是一次随机采样,根据中心极限定理,只有多次随机重复采样,才能得到比较稳定的结果。那么现在出现另一个问题,将随机排列去排序,这耗费很长的时间。于是这里使用了另一种方式,选择n 个hash 函数 $h_1$, $h_2$, $h_3$ .. $h_n$ 得到不同的签名矩阵,而不是将矩阵进行重新排序。
对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度。
就是说,对于两个document,在Min-Hashing方法中,它们hash值相等的概率等于它们降维前的Jaccard相似度。
minhash 的缺点
- 在工程中,不容易找到一系列的hash 函数,不同的hash 函数之间可能相关
- 局部敏感哈希是相对的,而且我们所说的保持数据的相似度不是说保持100%的相似度,而是保持最大可能的相似度。对于局部敏感哈希“保持最大可能的相似度”的这一点,我们也可以从数据降维的角度去考虑。数据对应的维度越高,信息量也就越大,相反,如果数据进行了降维,那么毫无疑问数据所反映的信息必然会有损失。哈希函数从本质上来看就是一直在扮演数据降维的角色。
simhash 有两个比较典型的应用:一个是网页抓取的排重,一个是检索时相似doc 的排重
simhash与Minhash的联系和区别:
相同点:simhash和minhash可以做到两个文档Hash之后仍然相似,但是simhash计算相似的方法是海明距离;而minhash计算距离的方式是Jaccard距离。 不同点:理论上讲,simhash 的准确率低于minhash。原因有二:
- simhash 对文本进行分词并统计词频,可以认为是一个词袋模型,没有统计词汇的先后顺序。而minhash 使用滑动窗口的方式,加入了词汇的词序信息。
- simhash 对词汇特征向量按列求和符号映射,丢失了文本特征信息。
参考资料:
https://www.cnblogs.com/maybe2030/p/4953039.html
这个也是比较好的: https://www.cnblogs.com/fengfenggirl/p/lsh.html
距离函数
这里的距离函数都是用来文本相似度。
Jaccard相似度
简单来说交集除以并集。这个集合中存放的是文章或者段落的关键词。
|
|
可以看到核心代码很简单,经过分词之后,就是seta 和setb 进行的操作。
Jaccard 系数 Jaccard相似指数用来度量两个集合之间的相似性,它被定义为两个集合交集元素个数除以两个集合并集元素个数。
$$ \mathrm { J } ( \mathrm { A } , \mathrm { B } ) = \frac { | A \cap B | } { | A \cup B | } $$ Jaccard距离用来度量两个集合之间的差异性m它是jaccard的相似系数的补集:
$$ d _ { J } ( A , B ) = 1 - J ( A , B ) = \frac { | A \cup B | - | A \cap B | } { | A \cup B | } $$ 利用jaccard相似度来衡量文档之间的相似性,使用LSH来实现文档相似度计算。
cosine
|
|
将文本的关键词映射成某种高维函数,然后在高维空间中计算两者的相似度。
tf-idf
在simhash 中使用 tf-idf作为我们的比较函数。TF-IDF的主要思想就是:如果某个词在一篇文档中出现的频率高,也即TF高;并且在语料库中其他文档中很少出现,即DF的低,也即IDF高,则认为这个词具有很好的类别区分能力。 $$ TF-IDF = 词频(TF) x 逆文档频率(IDF) $$
算法步骤:
-
计算词频 $$ 词频(TF) = 某个词在文章中出现的次数( 频数) $$ 或者可以进一步进行“标准化” $$ 词频( TF) = \frac{某次在文中出现的次数}{文章的总词语数} $$
-
逆文档频率(这对这个术语的还是好好记忆) 这个时候需要一个语料库 (corpus),模拟语言环境 $$ 逆文档频率 (IDF) = log(\frac{语料中的文档总数}{ 包含该词的文档数 +1}) $$
TF-IDF 优点是简单快速,比较符合实际。缺点,无法体现词的位置信息,所有的位置都是被认为重要性相同,但是开头结尾,段落的开头和段落的结尾,therefore,so,but这些词语都是没有体现的;还有一个缺点是,是基于统计的,没有表达出词语的语意信息 or context 上下文的信息。
Hamming distance
hamming distance就是比较01串的不同,按照位进行比较。算法:异或时,只有在两个比较的位不同时其结果是1 ,否则结果为0,两个二进制“异或”后得到1的个数即为海明距离的大小。
|
|
分词
在英文中存在天然的空格可以进行分词操作,但是中文的分词就比较复杂了。常用的中文分词开源工具有 jieba和HanLP 前者简单易行,容易上手;后者在自然语言处理作为汉语言处理包,可以用于词性标注,命名实体识别等一系列功能。常用的英文分词 corenlp
倒排索引
倒排索引使用python在实现上就是一个dictionary 嵌套一个 set(). 一般的索引都是数字或者英文字母映射内容,具体在放到simhash的情景下就是使用文章的序列号对应提取出来的关键词。但是倒排索引就是关键词对应文章的序列号,类似与原来的"值"对应这"键",所以称之为倒排索引。一般使用在召回的场景下,使用关键词然后出现了该关键词下的index 的集合。可以参考这篇文章。
一般的情况是key 是索引,value 对应的是关键词之列的内容; 但是倒排索引正好相反,关键字作为key,然后索引作为value,所以称之为倒排索引。
文章作者 jijeng
上次更新 2019-11-28