Text Summary
文章目录
Text Summarization
Text summarization is the process of distilling the most important information from a source (or sources) to produce an abridged version for a particular user (or users) and task (or tasks).
There are many reasons why Automatic Text Summarization is useful:
- Summaries reduce reading time.
- Automatic summarization algorithms are less biased than human summarizers.
- Personalized summaries are useful in question-answering systems as they provide personalized information.
Text summarization methods can be classified into different types.
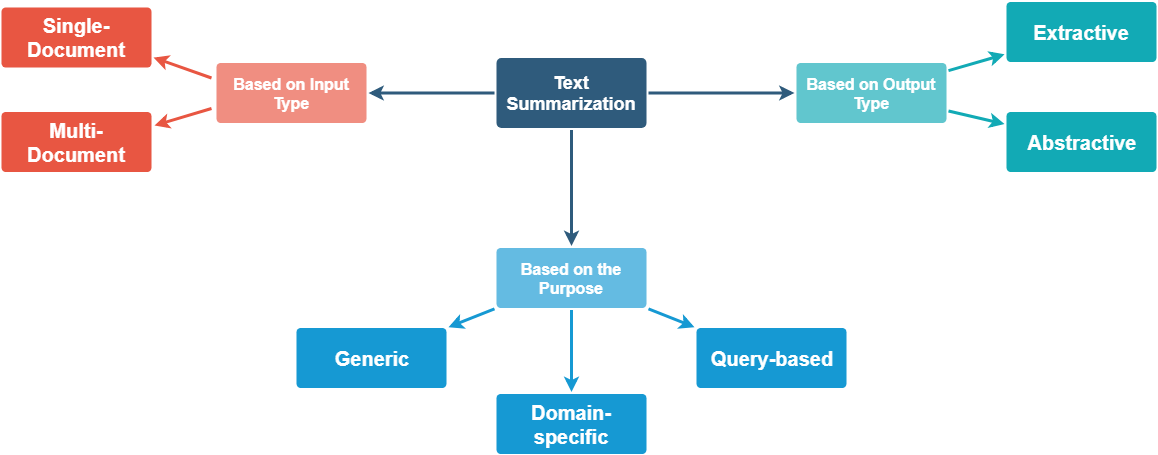
虽然是可以从不同的角度进行划分,但最常见的分类角度是 based on output type: extractive and abstractive. All extractive summarization algorithms attempt to score the phrases or sentences in a document and return only the most highly informative blocks of text. Abstractive text summarization actually creates new text which doesn’t exist in that form in the document. Abstractive summarization is what you might do when explaining a book you read to your friend, and it is much more difficult for a computer to do than extractive summarization.
extractive 是从源句子中找关键句的过程, abstractive 是概括,生成对于文章总结的过程。
Computers just aren’t that great at the act of creation. To date, there aren’t any abstractive summarization techniques which work suitably well on long documents. The best performing ones merely create a sentence based upon a single paragraph, or cut the length of a sentence in half while maintaining as much information as possible. Often, grammar suffers horribly. They’re usually based upon neural network models.
** What is ROUGE?** To evaluate the goodness of the generated summary, the common metric in the Text Summarization space is called Rouge score.
ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation
It works by comparing an automatically produced summary or translation against a set of reference summaries (typically human-produced). It works by matching overlap of n-grams of the generated and reference summary.
Extractive Techniques
** LexRank Summarizer** LexRank is an unsupervised approach that gets its inspiration from the same ideas behind Google’s PageRank algorithm. It finds the relative importance of all words in a document and selects the sentences which contain the most of those high-scoring words.
NLTK Summarizer
将句子的重要程度下放到词语 word 的关键程度。先是文本的预处理,然后挑选关键词,然后挑选关键句。

Although the technique is basic, we found that it did a good job at creating large summaries.
Gensim Summarizer
(pagerank 的思想很简单,每一个网页都是一种投票,然后被投票的重要程度越高,那么这个网页或者网站的重要性就越高,最后的排名就越靠前) TextRank is based on PageRank algorithm that is used on Google Search Engine. ***In simple words, it prefers pages which has higher number of pages hitting it. *** TextRank is a bit more simplistic than LexRank; although both algorithms are very similar, LexRank applies a heuristic post-processing step to remove sentences with highly duplicitous.
The gensim algorithm does a good job at creating both long and short summaries. Another cool feature of gensim is that we can get a list of top keywords chosen by the algorithm. This feature can come in handy for other NLP tasks, where we want to use “TextRank” to select words from a document instead of “Bag of Words” or “TF-IDF”. Gensim also has a well-maintained repository and has an active community which is an added asset to using this algorithm.
Sentence Embeddings (当源文本比较短的时候,比如 review 或者email, sentence embedding ,然后使用聚类的方式,得到不同的簇之后,每个簇可以选择一个句子,类似于降维的思想)
We wanted to evaluate how text summarization works on shorter documents like reviews, emails etc. We used K-means clustering to summarize the types of documents following the aforementioned structure.
Then, all of the sentences in a document are clustered in k = sqrt(length of document) clusters. Each cluster of sentence embeddings can be interpreted as a set of semantically similar sentences whose meaning can be expressed by just one candidate sentence in the summary.
Candidate sentences corresponding to each cluster are then ordered to form a summary for an email. The order of the candidate sentences in the summary is determined by the positions of the sentences in their corresponding clusters in the original document.
Abstraction techniques
** Pointer — Generator Networks**
Compared to the sequence-to-sequence-with-attention system, the pointer-generator network does a better job at copying words from the source text. Additionally it also is able to copy out-of-vocabulary words allowing the algorithm to handle unseen words even if the corpus has a smaller vocabulary.
Hence we can think of pointer generator as a combination approach combining both extraction (pointing) and abstraction (generating).
Drawbacks of Abstractive summarization
-
Firstly, training the model requires a lot of data and hence time.
-
An inherent problem with abstraction is that the summarizer reproduces factual details incorrectly. For instance, if the article talks about Germany beating Argentina 3–2, the summarizer may replace 3–2 by 2–0
-
Repetition is another problem faced by the summarizer. As we can see in the second example above, some phrases are repeated in the summary
To Summarize..
Given the architecture of RNNs and the current computing capabilities, we observed that extractive summarization methods are faster, but equally intuitive as abstractive methods. A few other observations:
- The network fails to focus on the core of the source text and summarizes a less important, secondary piece of information
- The attention mechanism, by revealing what the network is “looking at”, shines some precious light into the black box of neural networks, helping us to debug problems like repetition and copying.
- To make further advances, we need greater insight into what RNNs are learning from text and how that knowledge is represented.
Case Study: Text Summarization on Emails
Unsupervised Text Summarization using Sentence Embeddings

Step-1: Email Cleaning As salutation and signature lines (称谓签名行) can vary from email to email and from one language to the other, removing them will require matching against a regular expression.
Hi Jane,
Thank you for keeping me updated on this issue. I'm happy to hear that the issue got resolved after all and you can now use the app in its full functionality again.
Also many thanks for your suggestions. We hope to improve this feature in the future.
In case you experience any further problems with the app, please don't hesitate to contact me again.
Best regards,
John Doe
Customer Support
1600 Amphitheatre Parkway
Mountain View, CA
United States
Step-2: Language Detection
As the emails to be summarized can be of any language, the first thing one needs to do is to determine which language an email is in. I used ** langdetect** for my purpose and it supports 55 different languages.
Step-3: Sentence Tokenization Once the languages identification is performed for every email, we can use this information to split each email into its constituent sentences using specific rules for sentence delimiters (分隔符) for each language.
Step-4: Skip-Thought Encoder We need a way to generate fixed length vector representations for each sentence in our emails.
Step-5: Clustering (对于 最后summary 的长度,这个是一个很好的baseline,给出了一个定量的结果,使用 $ \sqrt{N}$, N 表示原始段落或者文章的长度) The number of clusters will be equal to desired number of sentences in the summary. I chose the numbers of sentences in the summary to be equal to the square root of the total number of sentence in the email.
Step-6: Summarization Each cluster of sentence embeddings can be interpreted as a set of semantically similar sentences whose meaning can be expressed by just one candidate sentence in the summary. The candidate sentence is chosen to be the sentence whose vector representation is closest to the cluster center. Candidate sentences corresponding to each cluster are then ordered to form a summary for an email.
PageRank 算法和TextRank 介绍
** PageRank 算法**
PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的。整个互联网可以看作是一张有向图,网页是图中的节点,网页之间的链接就是图中的边。如果网页 A 存在到网页 B 的链接,那么就有一条从网页 A 指向网页 B 的有向边。构造完图后,使用下面的公式来计算网页$ i$的重要性(PR值):
$$ S \left( V _ { i } \right) = ( 1 - d ) + d \cdot \sum _ { j \in I n \left( V _ { i } \right) } \frac { 1 } { \left| O u t \left( V _ { j } \right) \right| } S \left( V _ { j } \right) $$
$d$ 是阻尼系数,一般设置为0.85. $\operatorname { In } \left( V _ { i } \right)$ 是指向网页 $i$ 的链接的网页集合。 $\operatorname { Out } \left( V _ { j } \right)$ 是网页 $j$ 中的链接指向的网页的集合。 $\left| O u t \left( V _ { j } \right) \right|$ 是集合中元素的个数。 PageRank 需要多次迭代才能得到最后的结果。
(公式看着比较复杂,但是原理非常简单,如果计算网页 i的 pagerank,那么对于所有指向该网页的网站集合,进行权重的分摊。也就是说某个pageranking 很高的网站指向了某个网站,那么这个网站的pageranking 会变高,类似带有权重的投票)
 假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
| Webpage | Links |
|---|---|
| w1 | [w4, 22] |
| w2 | [w3, w1] |
| w3 | [] |
| w4 | [w1] |
在本例中初始化成这样:
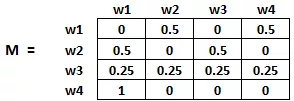
最后,这个矩阵中的值将以迭代的方式更新,以获得网页排名。
(上面的pageranking 的讲解是为了 下面的textranking 的理解) ** TextRank 关键词提取**
两者的相似之处:
- In place of web pages, we use sentences
- Similarity between any two sentences is used as an equivalent to the web page transition probability
- The similarity scores are stored in a square matrix, similar to the matrix M used for PageRank
不同之处在于后者使用句子之间的相似度作为 weights.
$W S \left( V _ { i } \right) = ( 1 - d ) + d \cdot \sum _ { V _ { j } \in \operatorname { In } ( V i ) } \frac { w _ { j i } } { \sum _ { V _ { k } \in O u t \left( V _ { j } \right) } w _ { j k } } W S \left( V _ { j } \right)$
$w_{ij}$ 就是图中节点 $V_i$ 到$V_j$ 的边的权值, 就是两个句子 $S_i$ 和句子 $S_j$ 的相似程度。下面的代码中使用的是 cosine 函数来表示这种相似度。

步骤:
- The first step would be to concatenate all the text contained in the articles
- Then split the text into individual sentences
- In the next step, we will find vector representation (word embeddings) for each and every sentence
- Similarities between sentence vectors are then calculated and stored in a matrix
- The similarity matrix is then converted into a graph, with sentences as vertices and similarity scores as edges, for sentence rank calculation
- Finally, a certain number of top-ranked sentences form the final summary
这里使用的 cosine similarity scores,计算句子之间的相似度,句子embedding 是通过 word embedding 相加而成。
|
|
Applying PageRank Algorithm
|
|
** TF-IDF 和 TextRank 对比总结:**
- TextRank与TFIDF均严重依赖于分词结果——如果某词在分词时被切分成了两个词,那么在做关键词提取时无法将两个词黏合在一起(TextRank有部分黏合效果,但需要这两个词均为关键词)。因此是否添加标注关键词进自定义词典,将会造成准确率、召回率大相径庭。
- TextRank的效果并不优于TFIDF。
- TextRank虽然考虑到了词之间的关系,但是仍然倾向于将频繁词作为关键词。
- 由于TextRank涉及到构建词图及迭代计算,所以提取速度较慢。
自然语言处理有两个切入点,一个是频率一个是语义。上述两种方法本质上还是基于词频的。如何进行方法的评价,如果是基于概率 (频率)进行计算,那么一个切入点是否能够体现上下文关系,是否有语义信息。如果是基于网络,那么一个方法就是内存和训练时间上是否可以在大规模的工业界展开使用。
References
https://medium.com/jatana/unsupervised-text-summarization-using-sentence-embeddings-adb15ce83db1
https://towardsdatascience.com/data-scientists-guide-to-summarization-fc0db952e363
https://www.jiqizhixin.com/articles/2018-12-28-18
https://www.analyticsvidhya.com/blog/2018/11/introduction-text-summarization-textrank-python/
https://xiaosheng.me/2017/04/08/article49/
复习总结
- 文本摘要有两种方法,一种是从源句子中抽取的过程,一种是概括的过程,生成对于文章总结的过程。
- pagerank 算法和 textrank 算法对于简历上的内容相关性不大,就先不复习了
文章作者 jijeng
上次更新 2019-06-30