Word_embedding_understanding
文章目录
从one-hot 到 word2vec, 到elmo,简单介绍一下 NLP中词向量的过程。
进入正题之前,思考为什么要将词用向量来表示呢?这样可以给词语一个数学上的表示,使之可以适用于某些算法或数学模型。通常将词语表示成向量有如下两种方法: one-hot and distributed 表示法。one-hot 只有一个位置是1 其他的位置都是0,最大的特点就是数据变得稀疏,而后者属于稠密向量。前者的缺点向量是相互独立的,无法通过距离函数比如 cosine 进行相似度的比较,并且如果维度 N非常大,那么高纬度的表示也可能引发维度灾难。于是接着往下看吧…
Traditional Word Vectors
Before diving directly into Word2Vec it’s worth while to do a brief overview of some of the traditional methods that pre-date neural embeddings.
这个是用来描述文章的,有一个大的dict,然后一片文章是如何进行表示、 Bag of Words or BoW vector representations are the most common used traditional vector representation. Each word or n-gram is linked to a vector index and marked as 0 or 1 depending on whether it occurs in a given document.
An example of a one hot bag of words representation for documents with one word.
 局限性: 一方面只是一种counter,没有考虑语义信息;另一方面有些 words 是明显的 relevant than others.
BoW representations are often used in methods of document classification where the frequency of each word, bi-word or tri-word is a useful feature for training classifiers. One challenge with bag of word representations is that they don’t encode any information with regards to the meaning of a given word.
In BoW word occurrences are evenly weighted independently of how frequently or what context they occur. However in most NLP tasks some words are more relevant than others.
局限性: 一方面只是一种counter,没有考虑语义信息;另一方面有些 words 是明显的 relevant than others.
BoW representations are often used in methods of document classification where the frequency of each word, bi-word or tri-word is a useful feature for training classifiers. One challenge with bag of word representations is that they don’t encode any information with regards to the meaning of a given word.
In BoW word occurrences are evenly weighted independently of how frequently or what context they occur. However in most NLP tasks some words are more relevant than others.
这个是可以认识是对于 bag of words “relevant” 上的改进:使得 选择的words 更加的 “representative” 文章的调性。 TF-IDF, short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word or n-gram is to a document in a collection or corpus. They provide some weighting to a given word based on the context it occurs.The tf–idf value increases proportionally to the number of times a word appears in a document and is offset by the number of documents in the corpus that contain the word, which helps to adjust for the fact that some words appear more frequently than others.
但是对于 bag of words 中“没有体现语义” 的缺陷还是没有 deal with。 However even though tf-idf BoW representations provide weights to different words they are unable to capture the word meaning.
这个名字只是因为有定义而存在的名字(网络模型 or 深度网络的出现就是为了 handle 语义信息) Distributional Embeddings enable word vectors to encapsulate contextual context. Each embedding vector is represented based on the mutual information it has with other words in a given corpus. 重点就是这种方式是要 predict a target word from context words,一定是要能够体现语境的。 Predictive models learn their vectors in order to improve their predictive ability of a loss such as the loss of predicting the vector for a target word from the vectors of the surrounding context words.
word2vec 两种类型
word2vec 是一种思想,有两种CBOW 和skip-gram 两种实现。Word2Vec is a predictive embedding model. There are two main Word2Vec architectures that are used to produce a distributed representation of words:
- Continuous bag-of-words (CBOW) — The order of context words does not influence prediction (bag-of-words assumption).
- Continuous skip-gram weighs nearby context words more heavily than more distant context words. While order still is not captured each of the context vectors are weighed and compared independently vs CBOW which weighs against the average context.
word2vec 就是2 种算法+ 2种模型,总共是四种实现。
展示一下结构图:
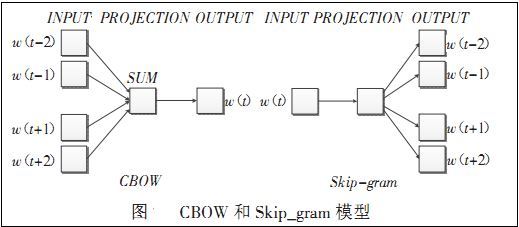
word2vec 的训练过程:
- 中文分词,然后保存所有的语料到一个文件中,可以使用 换行符进行分开
- 扫描语料库统计词频,取词频最高的V 个词,构成词汇表,one-hot 编码, 词的维度就是词典的大小,其余(出现频率很低)的词都用一个特殊符号代替掉。
- 词向量是从输入层到隐藏层的weights,随着初始化而存在,然后之后是不断优化的产物
- 训练的目标的,以skip-gram 为例,输入中心词然后最大化输出周围的词 (context )词汇。

输入层的输入:每个词存在一个one-hot向量,向量的维度是V(词典大小),如果该词在词汇表中出现过,则向量中词汇表中对应的位置为1,其他位置全为0。如果词汇表中不出现,则向量为全0
负采样(Negative Sample)和层次softmax(Hierarchical Softmax)则是两种加速训练的方法。都是优化最后的softmax 层(输出层),因为这个大小就是词典的大小,计算量太大了,如果知道softmax,是存在指数计算的。
loss function
在cbow模型中,所有的词被编码成ont-hot向量,V为总词语数。input层的one-hot vector经过 $W_{VXN} $矩阵后,被压缩为只有N个元素的向量h,之后经过W′矩阵出来,得到u。于是根据公式,有
$$ p \left( w _ { t } | w _ { \text {input} } \right) = y _ { j } = \frac { \exp \left( u _ { j } \right) } { \sum \exp \left( u _ { j } \prime \right) } $$
最大化该条件概率,得到
$$ \max p \left( w _ { t } | w _ { \text {input} } \right) = \max \log y _ { j } = u _ { j } - \operatorname { log } \sum \exp \left( u _ { j } \right) $$ 于是得到了 词袋模型的 loss function: (关于网络中的 loss function 还是要多留意一下的) $$ E = - \log p \left( w _ { t } | w _ { \text {input} } \right) = \log \sum \exp \left( u _ { j } \right) - u _ { j } $$ 这里,$u _ { j }$ 表示第 $j$ 个词向量, 有了 loss function,就可以进行词向量的训练了。
层次softmax
比如说一个二叉树结构,“我”肯定是第一层叶子节点,“涮羊肉”肯定是在最后一层的叶子节点。在 word2vec 中输入输出的编码都是使用的 one-hot 进行数字化表示的。
这个存储的目的是遍历的次数少了,因为是使用二分类去做多分类,如果词频高的编码少,那么最后的结果是比较少的。 word2vec训练的时候按照词频将每个词语Huffman编码,由于Huffman编码中词频越高的词语对应的编码越短。所以越高频的词语在 Hierarchical Softmax过程中经过的二分类节点就越少,整体计算量就更少了。
总的特点:使用 context words 去predict 中心词 or 相反的过程,最大化这种概率关系。CBOW is faster while skip-gram is slower but does a better job for infrequent words.那么为什么快呢?
答: cbow只要 把窗口内的其他词相加一次作为输入来预测 一个单词。不管窗口多大,只需要一次运算。而skip-gram直接受窗口影响,窗口越大,需要预测的周围词越多。在训练中,通过调整窗口大小明显感觉到训练速度受到很大影响。前者是复杂度大概是O(V),后者的时间的复杂度为O(KV)(假设K 是窗口的大小)
为什么skip-gram 的准确率高一些,对于生僻词的效果更好一些?
在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。因为尽管cbow从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动),进行词向量的跳帧,但是他的调整是跟周围的词一起调整的,grad的值会平均分到该词上, 相当于该生僻词没有收到专门的训练,它只是沾了周围词的光而已。
算法参数总体上对于效果影响不大,最重要的是语料。相对来说,比较重要的常用的参数:
min-count: (这个思想有点意思呀,切词切错了,那么在计算的时候就不要了)
最小词频训练阀值,这个根据训练语料大小设置,只有词频超过这个阀值的词才能被训练。根据经验,如果切词效果不好,会切错一些词,比如 “在深圳”,毕竟切错的是少数情况,使得这种错词词频不高,可以通过设置相对大一点的 min-count 过滤掉切错的词。(这种是对于新词处理的一种补救方法)
向量维度:
如果词量大,训练得到的词向量还要做语义层面的叠加,比如 句子 的向量表示 用 词的向量叠加,为了有区分度,语义空间应该要设置大一些,所以维度要偏大。一般来说,中文 180 就差不多了。
负采样:
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
任何采样算法都应该保证频次越高的样本越容易被采样出来。基本的思路是对于长度为1的线段,根据词语的词频将其公平地分配给每个词语: $$ \operatorname { len } ( w ) = \frac { \operatorname { counter } ( w ) } { \sum _ { u \in \mathcal { D } } \operatorname { counter } ( u ) } $$
在word2vec中,该“刻度尺”对应着table数组。具体实现时,对词频取了0.75次幂: $$ \operatorname { len } ( w ) = \frac { [ \operatorname { counter } ( w ) ] ^ { 0.75 } } { \sum _ { u \in \mathcal { D } } [ \operatorname { counter } ( u ) ] ^ { 0.75 } } $$ 这个幂实际上是一种“平滑”策略,能够让低频词多一些出场机会,高频词贡献一些出场机会,劫富济贫。
(这个是一种计算上的优化,通过选取一部分结点(词汇)更新权重)负采样越低,对高频词越不利,对低频词有利。可以这么理解,本来高频词 词被迭代50次,低频词迭代10次,如果采样频率降低一半,高频词失去了25次迭代,而低频词只失去了5次。一般设置成le-5. ( 这个就是 $10^{-5}$ ) 在 fasttext 实现的时候 使用下面的超参数记性控制。
-neg number of negatives sampled [5]
窗口大小:
窗口大小影响 词 和前后多少个词的关系,和语料中语句长度有关,建议可以统计一下语料中,句子长度的分布,再来设置window大小。一般设置成8。 (参数也是一个技术活,参数的设置和原始训练数据集 和其他的参数的配合是相关联的。如果句子比较长,那么window size 就不要太小)
负采样 vs 窗口大小
负采样主要是为了降低模型计算量。如果没有负采样,模型需要把词汇表中没有出现在滑动窗口的词语当作负样本。然而在实际训练过程中,并不需要这么多的负样本,过多的负样本会导致模型学偏。 (窗口的大小是正采样的个数,那么 负采样的个数和窗口的大小尽量是保持了 1:1 的关系,这样是比较好的)
负采样的个数和滑动窗口的比例尽量控制在0.1-10之间,滑动窗口决定了正样本的数量,负采样的个数决定了负样本的个数,正负样本尽量不要差距太大,建议负采样的个数和滑动窗口的比例控制为1:1。
比较详细的介绍可以查看这里
如何评估 word2vec 训练的好坏?
- 词聚类 (可以采用 kmeans 聚类,看聚类簇的分布)
- 词cos 相关性(查找cos相近的词)
- Analogy对比 (man-king, woman-queen)
- 使用tnse,pca等降维可视化展示
更多的评价方法可以参见这里.
glove (g lou v) (复习到这里了)
Intuition:
Both CBOW and Skip-Grams are “predictive” models, in that they only take local contexts into account. word2vec does not take advantage of global context. (细节 能看懂就看) GloVe embeddings by contrast leverage the same intuition behind the co-occurrence matrix (共生矩阵) used distributional embeddings, but uses neural methods to decompose the co-occurrence matrix into more expressive and dense word vectors.
模型目标:进行词的向量化表示,使得向量之间尽可能多地蕴含语义和语法的信息。 输入:语料库 输出:词向量 方法概述:首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。

下面是一个例子:
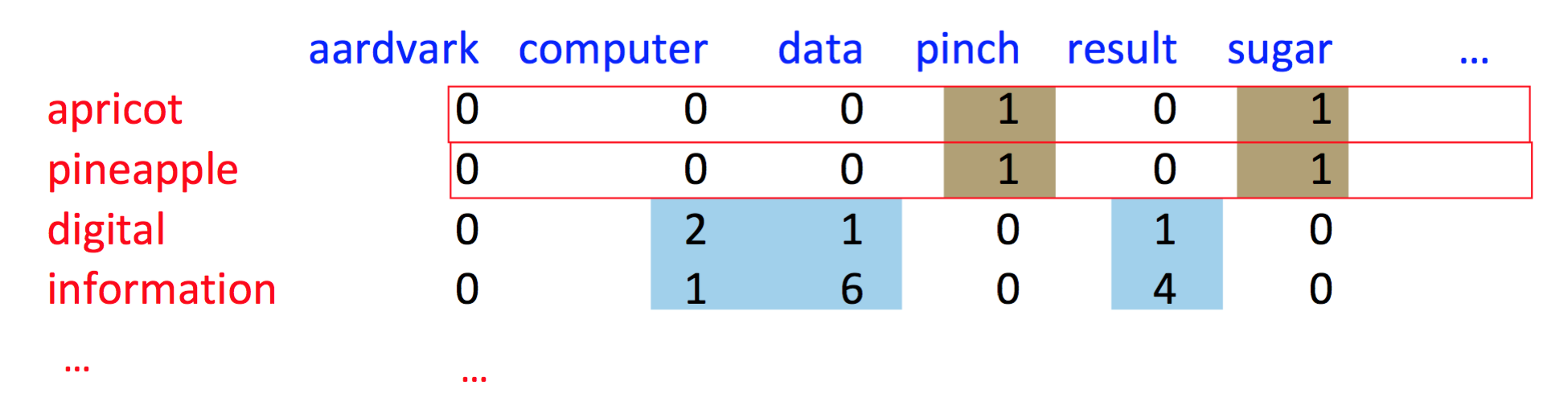
sparse vectors 词-文档矩阵(Term-document matrix) 和 词共现矩阵(Term-term matrix)。
Term-document matrix
表示每个单词在文档中出现的次数(词频),每一行是一个 term,每一列是一个 document
 两篇文档的向量相似 => 两篇文档相似,如上图 doc3 和 doc4,我们就认为它们是相似的。
两个单词的向量相似 => 两个单词相似,如上图的 fool 和 clown,就是相似的。
两篇文档的向量相似 => 两篇文档相似,如上图 doc3 和 doc4,我们就认为它们是相似的。
两个单词的向量相似 => 两个单词相似,如上图的 fool 和 clown,就是相似的。
Term-term matrix
然后我们可以考虑更小的粒度,更小的上下文,也就是不用整篇文档,而是用段落(paragraph),或者小的窗口(window of ±4 words),所以这个时候,向量就是对上下文单词的计数,大小不再是文档长度 |D|,而是窗口长度 |V| 了,所以现在 word-word matrix 是 |V|*|V|
而 word2vec 得到的向量 dense vectors。不使用 negative sampling 的Wordvec 非常快,但准确率不高(57.4%),毕竟模型没有告诉什么是无关的word,模型很难对无关词汇进行惩戒,提高准确率。对于 synonym 问题,word2vec 是好于 glove,但从最终的效果上看,两者是不分彼此的。glove 使用了整体的信息,word2vec 只是使用了局部信息(local context)。
word2vec 和glove 的区别: Predictive的模型,如Word2vec,根据context预测中间的词汇,要么根据中间的词汇预测context,分别对应了word2vec的两种训练方式cbow和skip-gram。
Count-based模型,如GloVe,本质上是对共现矩阵进行降维。首先,构建一个词汇的共现矩阵,每一行是一个word,每一列是context。共现矩阵就是计算每个word在每个context出现的频率。由于context是多种词汇的组合,其维度非常大,我们希望像network embedding一样,在context的维度上降维,学习word的低维表示。该向量表示属于 sparse vectors
和word2vec 的效果比较: glove 和word2vec 相比没有 definitively better results,还是通过实验进行说话吧。 While GloVe vectors are faster to train, neither GloVe or Word2Vec has been shown to provide definitively better results rather they should both be evaluated for a given dataset.
fasttext 这个主要是 each word + n-gram within each word, 最后的效果是好于 word2vec 的。 FastText, builds on Word2Vec by learning vector representations for each word and the n-grams found within each word. The values of the representations are then averaged into one vector at each training step. While this adds a lot of additional computation to training it enables word embeddings to encode sub-word information. FastText vectors have been shown to be more accurate than Word2Vec vectors by a number of different measures.
简单说 fasttext 和word2vec 模型上的不同有两点:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是 分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用; fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)
- 模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext对应的整个sentence的内容,包括term,也包括 n-gram的内容
更多信息可以参看博客。
overview of Neural NLP Architectures
Deep Feed Forward Networks
1D CNNs
RNNs (LSTM/GRU)
encoder- decoder 结构
attention and copy mechanisms 这个是 attention 机制提出的背景:解决 句子中的长依赖;contextual impact (specific words may carry more importance at different steps) While in theory they can capture long term dependencies they tend to struggle modeling longer sequences, this is still an open problem.
One cause for sub-optimal performance standard RNN encoder-decoder models for sequence to sequence tasks such as NER or translation is that they weight the impact each input vector evenly on each output vector when in reality specific words in the input sequence may carry more importance at different time steps. Attention mechanisms provide a means of weighting the contextual impact of each input vector on each output prediction of the RNN. These mechanisms are responsible for much of the current or near current state of the art in Natural language processing.
attention
In sum, algorithms can allocate attention, and they can learn how to do so, by adjusting the weights they assign to various inputs. Imagine a heat map over a photo. The heat is attention.
这个是要引出来 context word embeddings. One of the limits of traditional word vectors is that they presume that a word’s meaning is relatively stable across sentences. 并不是物理上的二维关系能够表示词语之间的 relationship,有时候是需要高纬空间进行表示的。 In fact, the strongest relationships binding a given word to the rest of the sentence may be with words quite distant from it. 从 credit assignment的角度阐述了 neural networks 就是 allocating importance to input features。 The fundamental task of all neural networks is credit assignment. Credit assignment is allocating importance to input features through the weights of the neural network’s model. Learning is the process by which neural networks figure out which input features correlate highly with the outcomes the net tries to predict, and their learnings are embodied in the adjusted quantities of the weights that result in accurate decisions about the data they’re exposed to. 这个是传统的 LSTM (encoder -decoder) 模型,问题在于当句子过长(比如说大于20 words)之后,encoder 是无法 memory 之前的所有 words,所以效果就会变得差一些。

但是 attention 就是模仿了人翻译过程,一段作为一个单位,然后进行翻译。这样就可以持续保证较高中确率的输出。
In neural networks, attention primarily serves as a memory-access mechanism.
 每次的输出都是关注不同的地方,但是至于哪里更加重要,这个交给了 feedback mechanism 反向传播。下面的图片十分清晰的展示了 在翻译的过程中 “focus” 是不断地变化的。
Above, a model highlights which pixels it is focusing on as it predicts the underlined word in the respective captions. Below, a language model highlights the words from one language, French, that were relevant as it produced the English words in the translation. As you can see, attention provides us with a route to interpretability. We can render attention as a heat map over input data such as words and pixels, and thus communicate to human operators how a neural network made a decision. (This could be the basis of a feedback mechanism whereby those humans tell the network to pay attention to certain features and not others.)
(This could be the basis of a feedback mechanism whereby those humans tell the network to pay attention to certain features and not others.)
每次的输出都是关注不同的地方,但是至于哪里更加重要,这个交给了 feedback mechanism 反向传播。下面的图片十分清晰的展示了 在翻译的过程中 “focus” 是不断地变化的。
Above, a model highlights which pixels it is focusing on as it predicts the underlined word in the respective captions. Below, a language model highlights the words from one language, French, that were relevant as it produced the English words in the translation. As you can see, attention provides us with a route to interpretability. We can render attention as a heat map over input data such as words and pixels, and thus communicate to human operators how a neural network made a decision. (This could be the basis of a feedback mechanism whereby those humans tell the network to pay attention to certain features and not others.)
(This could be the basis of a feedback mechanism whereby those humans tell the network to pay attention to certain features and not others.)

Additionally in Machine Reading Comprehension and Summarization systems RNNs often tend to generate results, that while on first glance look structurally correct are in reality hallucinated or incorrect. One mechanism that helps mitigate some of these issues is the Copy Mechanism. copy mechanism 简单说来就是 word embedding or raw text. The copy mechanism is an additional layer applied during decoding that decides whether it is better to generate the next word from the source sentence or from the general embedding vocabulary.
reading comprehension and summary
上面是说的在 machine translation,下面说的是 阅读理解 和 summary领域。 Additionally in Machine Reading Comprehension and Summarization systems RNNs often tend to generate results, that while on first glance look structurally correct are in reality hallucinated or incorrect. One mechanism that helps mitigate some of these issues is the Copy Mechanism. copy mechanism 简单说来就是 decide word embedding from model or raw text. The copy mechanism is an additional layer applied during decoding that decides whether it is better to generate the next word from the source sentence or from the general embedding vocabulary.
Taming Recurrent Neural Networks for Better Summarization 有两种不同的 summarization: Two types of summarization:Extractive (You might think of these approaches as like a highlighter.) Abstractive(By the same analogy, these approaches are like a pen.) The great majority of existing approaches to automatic summarization are extractive – mostly because it is much easier to select text than it is to generate text from scratch. 但是一个问题在于,只是使用 extrative way 可能得到相同的words, Problem 1: The summaries sometimes reproduce factual details inaccurately (e.g. Germany beat Argentina 3-2). This is especially common for rare or out-of-vocabulary words such as 2-0. Problem 2: The summaries sometimes repeat themselves (e.g. Germany beat Germany beat Germany beat…) Easier Copying with Pointer-Generator Networks。这个跟 attention 不是很相关,简单说就是In this way, the pointer-generator network is a best of both worlds, combining both extraction (pointing) and abstraction (generating).
To tackle Problem 2 (repetitive summaries), we use a technique called coverage. The idea is that we use the attention distribution to keep track of what’s been covered so far, and penalize the network for attending to same parts again.
elmo (e l mo) elmo 产生一个 embedding 是根据 context 产生的。 ELMo is a model generates embeddings for a word based on the context it appears thus generating slightly different embeddings for each of its occurrence. (感觉理解一个概念都是 根据其 for example 进行理解的) For example, the word “play” in the sentence above using standard word embeddings encodes multiple meanings such as the verb to play or in the case of the sentence a theatre production. In standard word embeddings such as Glove, Fast Text or Word2Vec each instance of the word play would have the same representation.
http://www.abigailsee.com/2017/04/16/taming-rnns-for-better-summarization.html
https://skymind.ai/wiki/word2vec
复习笔记
-
评价 word embedding的方面:是否能体现语义信息;是否比其他词语更加具有代表性;
-
word2vec(或者说 CBOW or Skip-gram )的特点,输入和输出都是 one-hot 的表示,长度都是字典的长度,在某一个位置是1,其他的位置都是0. 训练过程:分词之后组成预料库,扫描所有的词频,取词频最高的V个词语,构成词汇表,词频低的就会被丢弃(所以词语的学习需要多次的,有上下文的), 都被用一个特殊符号代替掉。损失函数是概率模型,给定上下文然后中心词出现的概率,概率是需要加上log,就组成了loss function,训练的过程中是最大化概率模型(最小化loss)。CBOW和Skip-gram 的区别:CBOW在训练的过程中将上下文加和成一个向量表示,所以最后的训练速度是快于skip-gram 但是效果没有skip-gram。后者是一个个单词进行训练的(当然训练时间也是比较长的)。对于中文的embedding size,一般180 就OK了。在负采样中负样本是根据词频挑选的,但公式中使用了一种平滑机制,使得低频词也有了一些机会,对高频词语进行了一些约束。
-
word2vec 和glove 的区别:前者是预测类的模型,后者是cout-base的模型,本质上是对共现矩阵的降维处理。每一行表示一个word,每一列表示context,共现矩阵就是计算每个word 在每个context 中出现的频率。
-
fasttext 和word2vec 的区别:输入层,word2vec 是一个term,而fasttext中包含的是term和对应的n-gram的特征;输出层, 在分类中fasttext的输出是label 信息。
文章作者 jijeng
上次更新 2019-05-22